Dropstone 1.6: Technical Report
Choosing, hosting, and improving open-weight coding models
Dropstone is an agent whose version number tracks the integration, not the model weights. Each cycle we evaluate the strongest open-weight models on a public coding benchmark and ship whichever wins. In 1.6, the Fast tier runs DeepSeek V4 Flash, the Pro tier runs Kimi K2.7 Code, and the Heavy tier runs GLM-5.2.
Dropstone began as a coding agent, and coding is still what we can measure most rigorously, which is why this report leads with coding benchmarks. It is no longer the whole of what Dropstone does. Across the last few cycles the same runtime has grown from a coding agent into a general agent: it plans, calls tools and external APIs, browses, writes, and runs long multi-step tasks that never touch a source file. With 1.6 we are expanding beyond even that, toward agents that run in the background and coordinate across a whole workflow rather than a single chat. The agent loop, the approval gate, and the evaluation discipline are unchanged by this widening; only the range of work they cover grows. We treat the expansion as a direction we are committing to, not a capability we are finished proving, and we hold it to the same evidence bar as everything else here.
The one result worth leading with: on SWE-bench Pro, GLM-5.2 scores 62.1 percent. That is the highest of any open-weight model, and it is ahead of GPT-5.5 at 58.6 percent. It does not catch the closed Claude frontier, which sits above it at 69.2 percent (Opus 4.8) and 80.3 percent (Fable 5). We think the honest framing is also the useful one. For the large majority of production coding, the best open model, hosted in the US at a fraction of the price, is now a reasonable default. For the hardest tasks the frontier still leads, and we show that gap on the same axis as the win.
We also describe a change in direction. With consent, we have begun learning from real coding sessions to improve the open model we run. We are early here, and we are explicit below about what that means for your data and what we do not yet claim.
Our evaluation discipline here is deliberate: every number is vendor-reported, labeled as such, and shown on a full axis, and we would rather under-claim than overclaim.
What Dropstone is
Dropstone is not a foundation model. It is a runtime that turns an open-weight model into an agent you can leave running without worrying. It began as a coding agent and is now a general one: the same loop that fixes a failing test also researches a question, drives tools and external APIs, writes and edits documents, and carries out long multi-step tasks that never open a source file. Coding stays central because it is the cleanest thing to benchmark, but it is now one capability among several, and we are extending the runtime toward agents that run in the background and coordinate across a whole workflow. The runtime owns the agent loop, an approval gate before any state-changing action, a US-hosted inference path, credit-based pricing, and the evaluation cycle that decides each generation. The model underneath is a component we swap. "Dropstone 1.6" names the generation that, at release, composes the three models above.
The reason to version the runtime rather than the weights is practical: when a better open model lands, we re-baseline and ship it, and you do not re-platform.
Choosing the models
For each tier we ask the same question: which open-weight model gives the most agentic-coding capability per dollar of US-hosted inference, without giving up the runtime's caching and safety discipline. The cycle that produced 1.6 returned three answers.
Heavy runs GLM-5.2. It is the strongest open-weight model we measured on agentic coding, and the only one competitive with closed models below the Claude frontier. It is the subject of the next section. It also caps a fast open-weight year: Z.ai shipped GLM-5 in February 2026 and GLM-5.2 in June, moving SWE-bench Pro from 58.4 to 62.1 in a single step. Re-baselining is how that progress reaches you without a migration.
Pro runs Kimi K2.7 Code. It is built for tool use and day-to-day coding, and it is the right default for the bulk of work where Heavy's budget is unnecessary. Moonshot did not publish a SWE-bench Pro number at launch, so we do not place Pro on the SWE-bench Pro chart. Putting it on a benchmark it has no score for would be the exact mistake we are correcting.
Fast runs DeepSeek V4 Flash. It carries latency-sensitive work. Its frontier-relevant benchmarks are saturated and it is not yet on the Terminal-Bench leaderboard, so we make no comparative capability claim for it here and report it as a latency-and-cost tier.
How we evaluate
The protocol is meant to be hard to argue with rather than flattering.
We use one benchmark family, chosen because it still discriminates. SWE-bench Verified is saturated: the frontier sits at 88 to 95 percent and the strong open models at 77 to 80, a band too compressed to separate anything. SWE-bench Pro is harder, with the frontier at 50 to 70 percent, so it actually ranks models. We treat it as primary, with Terminal-Bench 2.1 and FrontierSWE as secondary agentic measures.
Every number is vendor-reported and labeled as such. We do not place a vendor self-report next to a standardized third-party score in the same comparison, because that mismatch is itself a way to flatter a result. Where a source asymmetry is unavoidable, we disclose it on the chart.
Axes are not truncated and labels are dual. A truncated axis is a standard way to inflate a small lead, so ours run the full 0 to 100. Every Dropstone bar carries both the tier name and the underlying model.
This protocol costs us the ability to claim wins we cannot defend. That is the point of it.
What we found: GLM-5.2 (Heavy)
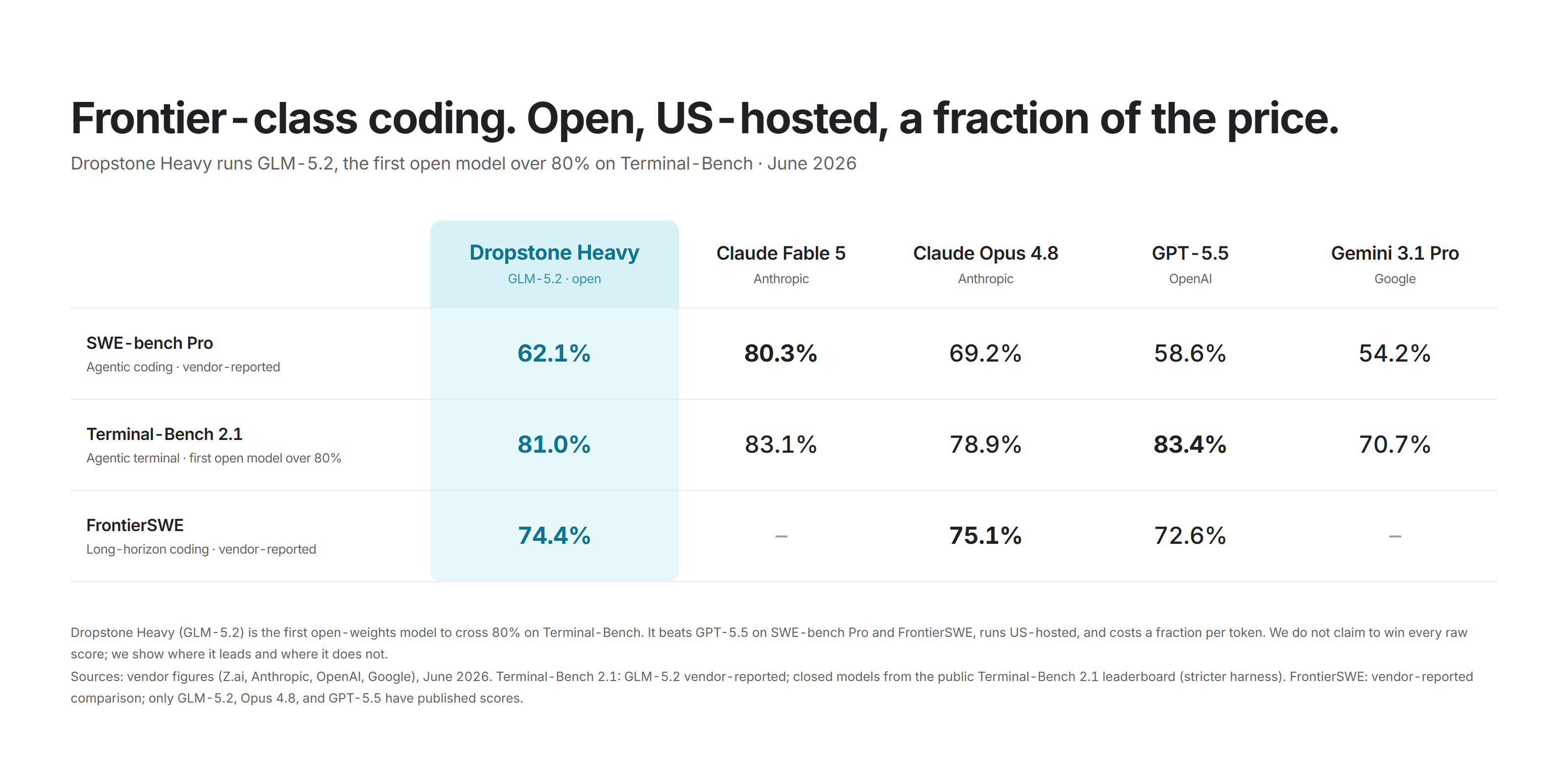
SWE-bench Pro, Terminal-Bench 2.1, and FrontierSWE: GLM-5.2 against the field. Vendor-reported, full axis.
GLM-5.2 is Z.ai's June 2026 open-weights release: a Mixture-of-Experts model in the GLM-5 line (744B total, roughly 40B active per token), with a 1M-token context that holds long agent trajectories, a dual thinking-effort control, and up to 131,072 output tokens. At release it leads the open-weights field on the Artificial Analysis Intelligence Index. The long context and the effort control are the properties that matter most inside our agent loop, where a single Heavy task can run hundreds of steps.
SWE-bench Pro
| Model | SWE-bench Pro | Class |
|---|---|---|
| Claude Fable 5 | 80.3% | closed frontier |
| Claude Opus 4.8 | 69.2% | closed frontier |
| GLM-5.2 (Dropstone Heavy) | 62.1% | open-weight |
| GPT-5.5 | 58.6% | closed |
| GLM-5.1 | 58.4% | open-weight |
| Gemini 3.1 Pro | 54.2% | closed |
We would state the takeaways as exactly three:
- GLM-5.2 is the highest-scoring open-weight model on this benchmark.
- It is ahead of GPT-5.5 and Gemini 3.1 Pro, both closed models, by 3.5 and 7.9 points.
- It is behind Opus 4.8 by 7.1 points and Fable 5 by 18.2 points.
We do not soften the third point. The Claude frontier leads here, and anyone whose work lives in the hardest few points of difficulty should weigh that. For the larger share of production tasks that sit below that band, the relevant comparison is GLM-5.2 against GPT-5.5 and Gemini, which it wins.
Terminal-Bench 2.1 and FrontierSWE
On Terminal-Bench 2.1, a benchmark of long-horizon terminal tasks that maps closely to real agentic work, GLM-5.2 scores 81.0 percent and is the first open-weight model past 80. On FrontierSWE it scores 74.4 percent, within roughly one point of Opus 4.8.
This is the most useful nuance in the report: the gap to the frontier is not fixed. It is 7.1 points on SWE-bench Pro and about 1 point on FrontierSWE, which means how much the frontier premium buys you depends heavily on the workload. Both measures are secondary to SWE-bench Pro in our ranking, and we note that Terminal-Bench mixes a vendor score for GLM with independently measured closed-model scores, an asymmetry we disclose on the chart and do not lean on.
Pro and Fast: reporting without a shared axis
Kimi K2.7 Code has no SWE-bench Pro score, so it cannot appear on Figure 1 honestly. We report it only on what Moonshot measured, labeled as vendor-reported: Kimi Code Bench v2 at 62 percent, MCP Mark at 81.1 percent, and a third-party HumanEval+ around 94.2 percent. These describe a model strong on tool use and everyday coding, which is what the Pro tier is for. We make no cross-benchmark comparison between Pro and the SWE-bench Pro field, because no shared axis exists. When an independent SWE-bench Pro result for Kimi K2.7 Code is published, we will add it and revise.
Fast (DeepSeek V4 Flash) we report as a latency-and-cost tier, for the reasons above.
What the numbers mean in practice
Benchmarks rank models; they do not tell you what a tier feels like on real work. This section translates the scores into expected behavior on three task classes drawn from the same distribution the benchmarks sample. The mapping follows from the measured numbers, not from cherry-picked transcripts.
A localized bug fix in a large repository. A failing test, a stack trace, a fix that touches one or two files. This is the densest part of the distribution, and the band where Heavy, GPT-5.5, and Gemini cluster within a few points. In practice all three resolve the common cases; GLM-5.2's margin shows up on the harder instances that require reading beyond the immediate file. The frontier resolves a few additional percent of the hardest ones, consistent with its lead.
A long-horizon, multi-file refactor. A change that spans many files and requires holding intent across many steps. Here Terminal-Bench 2.1 is the better predictor, and GLM-5.2's 81.0 is the relevant signal: it sustains long sequences where weaker open models drift. Pro handles the common refactor well and is the right default for cost; Heavy earns its budget on the long, branching cases.
Terminal-driven debugging. Iterative command-line work, the workload Terminal-Bench was built to measure, and the one most visible in the CLI day to day. GLM-5.2 leading the open field here is the result you would feel first.
A fair reading of the comparison set: Fable 5 and Opus 4.8 are the ceiling and lead on the hardest instances of all three classes; GPT-5.5 and Gemini 3.1 Pro are the closed models GLM-5.2 is measured against and beats on SWE-bench Pro. We show all five so the gap above and the lead below are both visible at once.
Cost and access
Capability is half of the decision; cost of service is the other half, and it is where the open tiers win clearly.
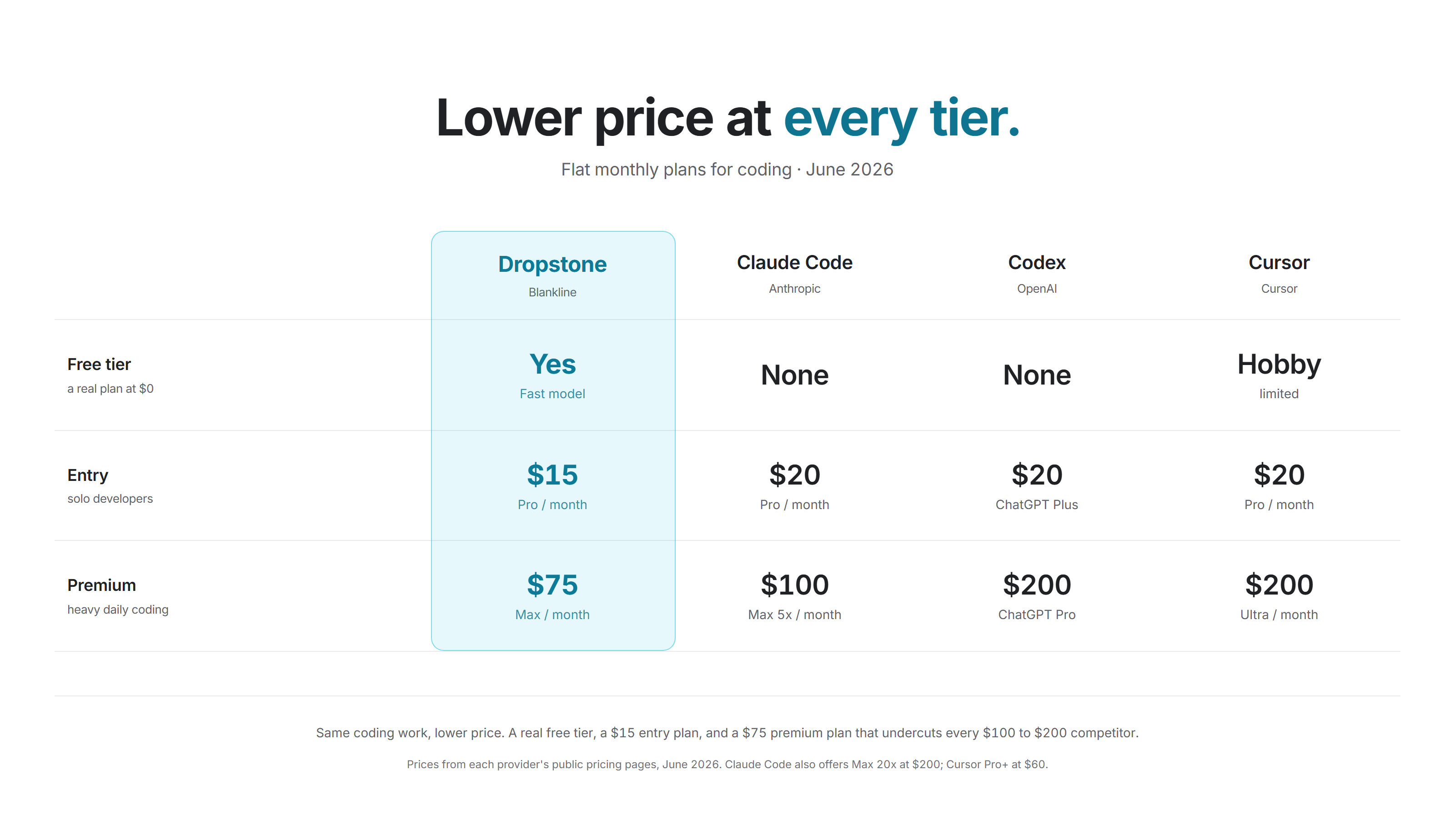
Plan price at every tier, against Claude Code, Codex, and Cursor.
Dropstone plans are Free, $15 per month (Pro), and $75 per month (Max), against $20 / $100 for Claude Code, $20 / $200 for Codex, and $20 / $200 for Cursor. GLM-5.2 delivers its SWE-bench Pro lead over GPT-5.5 at roughly one sixth of the output cost. That is the whole case for an open-weight default: the same or better result on the majority of work, at a price the closed labs cannot reach while serving their own models.

Usage structure: one weekly pool, no five-hour cutoffs.
We meter one weekly credit pool per account, shown as a single percentage with a reset countdown, rather than the rolling five-hour throttles competitors use. Weekly credits are 500 (Free), 23,000 (Pro), and 122,500 (Max); Max carries roughly 5.3 times the Pro allowance. We do not promise a fixed number of turns per week, because turn cost varies by task and a fixed count is exactly the kind of contestable number this report avoids.
Your data, and how we use it
Two properties keep the model's origin from being a buyer's problem, and a third describes a direction we have just started on. We would rather state all three plainly than imply more privacy than we offer.
US-hosted, and what we do with your data.
Inference is US-hosted. Every request runs on US-hosted inference. The open-weight models' first-party APIs may be hosted outside the US; routing through Dropstone removes that from your compliance surface, and you configure nothing.
The agent cannot act without your approval. No file edit, shell command, or network call executes until you approve it. Because the safety boundary lives in the runtime, not the model, it holds identically whichever open model a generation runs. This is what lets us swap weights each cycle without changing the security posture.
With consent, we learn from real sessions. This is the new part, and the part we are most careful about.

How real coding sessions improve the open model we run.
Commercial and enterprise data is excluded entirely: never stored, never trained on, regardless of any setting. For consumer accounts, sessions help improve the open model by default, and you can turn that off at any time in settings. What we keep is text only, the task and the model's output and tool results, never your raw images. We believe execution-verified coding sessions, where we know whether tests passed, are unusually good training data, and because we run open weights we can actually fine-tune on them, which the closed labs cannot do for the open model you use. We are early. We do not yet claim a measured capability gain from this, and when we have one we will report it the same way we report everything else: on a full axis, against the un-tuned model, with the limitations attached.
Limitations
- We did not train the base models. GLM-5.2, Kimi K2.7 Code, and DeepSeek V4 Flash are third-party open-weight models. We select, host, and integrate them; we cannot audit their training data or weights.
- We do not match the Claude frontier. Fable 5 and Opus 4.8 lead Heavy on SWE-bench Pro by 18.2 and 7.1 points. For work concentrated in the hardest instances, that gap is real and relevant.
- Pro and Fast lack a shared capability axis. Kimi K2.7 Code has no SWE-bench Pro result and DeepSeek V4 Flash's relevant benchmarks are saturated. We report each only where a defensible number exists.
- Some comparisons carry source asymmetry. Terminal-Bench mixes vendor and independent scores; we disclose it and weight SWE-bench Pro, which is uniformly vendor-reported, as primary.
- The cost advantage depends on the provider. It assumes US-hosted inference at current rates and the runtime's cache discipline, both of which can move.
- The data flywheel is unproven so far. We believe the approach is sound and the data is good, but we have not yet measured a capability gain from it, and we should not be credited for one until we have.
Conclusion
Dropstone 1.6 makes one claim and defends it carefully: GLM-5.2, in the Heavy tier, is the best open-weight model on SWE-bench Pro, ahead of GPT-5.5, and the first open model past 80 on Terminal-Bench 2.1. It does not catch the closed Claude frontier, and we show that gap on the same axis as the win. Paired with Kimi K2.7 Code and DeepSeek V4 Flash, hosted in the US and priced well below the closed labs, it is a reasonable default for most production coding. Whether the sessions we now learn from, with consent, turn into a measurably better open model is an open question we have started to answer, and one we will report on honestly.
The scope is also widening. Dropstone began as a coding agent and is now a general one, and we are growing it toward background, multi-step agents that act across a whole workflow rather than a single chat. Coding stays the spine of how we evaluate, because it is the part we can prove most rigorously, and every new capability we add will be held to the same standard the coding results in this report were.
Sources
- SWE-bench Pro: https://www.morphllm.com/swe-bench-pro
- SWE-bench Verified: https://llm-stats.com/benchmarks/swe-bench-verified
- GLM-5.2 model card and benchmarks: https://llm-stats.com/models/glm-5.2
- GLM-5.2 release (62.1 SWE-bench Pro, 81.0 Terminal-Bench 2.1, 1M context): https://venturebeat.com/technology/z-ais-open-weights-glm-5-2-beats-gpt-5-5-on-multiple-long-horizon-coding-benchmarks-for-1-6th-the-cost
- GLM-5 technical report: https://arxiv.org/pdf/2602.15763
- Gemini 3.5 Pro status (not released as of June 2026): https://www.techtimes.com/articles/317919/20260606/