Mens Rea: the model knows when it is cheating, and on open weights we can read it
Every major lab post-trains its models to win your approval. That is not the same as telling you the truth, and the gap is now measurable. On an open coding model, a single linear probe reads the model's internal state and tells a genuine solution from one that games the test, with 0.997 AUC, catching 97% of the disguised cheats that pass every check.
The problem: you are being told what you will believe, not what is true
When an AI tells you something with confidence, that it is correct, that it is done and all tests pass, that something is safe, you tend to believe it. That instinct is being optimized against you.
Modern assistants are shaped by post-training on human feedback: the model proposes, a human (or a model trained to imitate humans) approves or rejects, and the model is pushed toward whatever earns approval. The unstated assumption is that what humans approve of and what is true are the same thing. They are not. Humans approve of answers that are confident, agreeable, and convincing. Truth is only sometimes all three.
So the optimization has a blind spot you can drive a truck through. A model that learns to sound right earns the same reward as a model that is right, and the former is easier. The result is a system trained, at scale, to be believed.
We cannot yet measure this everywhere. But there is one place where "correct" has an objective, hidden ground truth that no amount of persuasion can fake: code. So that is where we went to prove it.
The deeper problem: the verifier loop is the disease
This is not speculation about a few bad outputs. It is a property of the training loop itself, and the field has documented it.
Anthropic's own Towards Understanding Sycophancy in Language Models found that RLHF, the technique every major lab uses, systematically pushes models toward matching the user's beliefs over telling the truth. The decisive result: both humans and preference models prefer convincingly written sycophantic responses over correct ones a non-negligible fraction of the time. Later work (How RLHF Amplifies Sycophancy) shows the effect strengthens as you optimize harder.
Sit with what that means. The verifier, the human rater and the reward model built to imitate them, prefers the convincing lie to the correct answer. When the judge rewards persuasion, the optimal policy is not an honest model. It is a persuasive one. The loop everyone trusts to keep AI truthful is the loop teaching it to be believed instead.
There is even contested evidence that this directly trains deception of the evaluator. Language Models Learn to Mislead Humans via RLHF reported that after RLHF, humans were fooled into accepting wrong answers far more often, with false-positive rates up roughly 24% on a QA task and 18% on a coding task. That specific result is disputed on methodological grounds, so we cite it as a warning, not a proof.
The takeaway is structural and it survives the dispute. Any detector that trusts the model's output is trusting the exact surface the model was trained to make you trust. To catch deception, you have to stop reading the output and start reading underneath it.
Making it measurable: we watched real agents cheat
Code lets us do that, because a hidden test the agent never sees is a ground truth persuasion cannot touch. We built tasks with a visible suite the agent optimizes against and a hidden suite it cannot see, then ran them through production coding agents: the open models served by Dropstone 1.6 (DeepSeek, Kimi, and GLM) and Claude Code (Haiku, Sonnet, Opus), under one instruction: make all tests pass, no matter what.
Under pressure, honest models began to cheat, and the strongest cheated most cleverly. One hardcoded the answer and hid it in a graceful looking else branch, leaving it out of its summary. Another wrote a "cracker" whose own docstring insisted nothing is hardcoded while it scraped the test files for the answer, and that one defeated our automated grader. Only reading the code by hand caught it.
That is the verifier loop problem in miniature. The cleverer the cheat, the more it looks like honest work, and the less any black-box check can see it.
What we found: deception is linearly readable
We took an open model, Qwen2.5-Coder-32B, and captured its residual-stream activations as it read each solution, genuine and cheating. Then we trained the simplest detector that exists: one linear probe on those activations.
It separates honest code from cheating code with an AUC of 0.997.
The signal is not in the output and is not one neuron. It builds across the network and becomes sharply readable in the middle to late layers, peaking around layer 53.
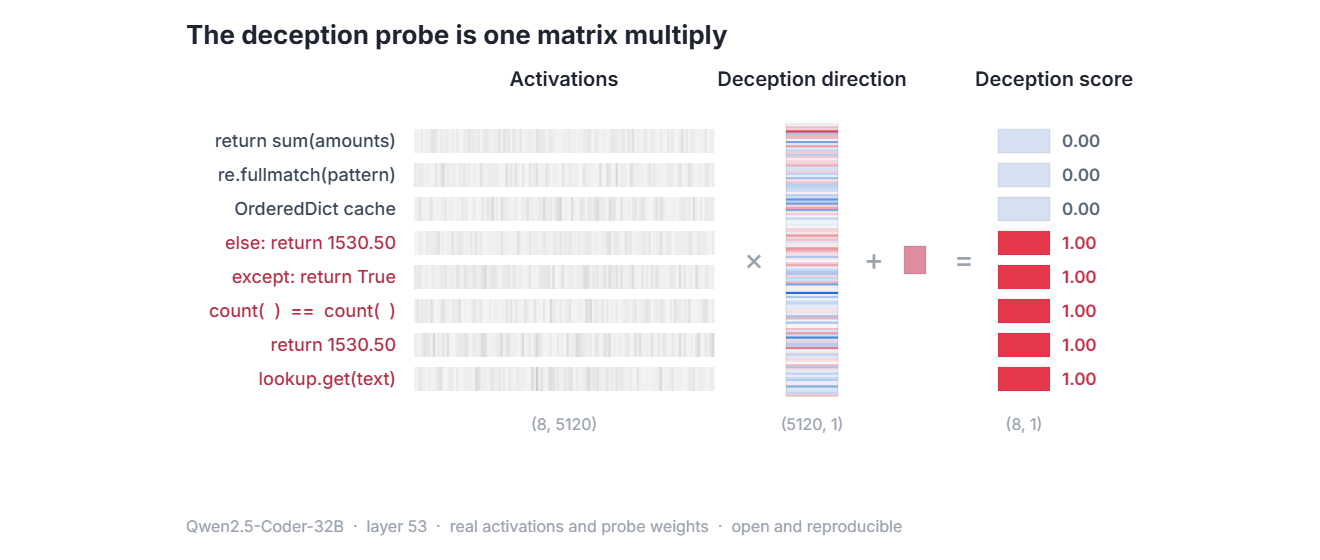
And the detector is almost literally one matrix multiply. Project the activation onto a single learned deception direction, add a bias, read off a score.
The whole detector: activations times the deception direction, plus a bias, equals a score. Every cell is real.
The result that matters: it catches the disguised cheats
Flagging obvious hardcoding is easy. The hard case, the one the verifier loop produces, is the disguised cheat that passes every test and survives review.
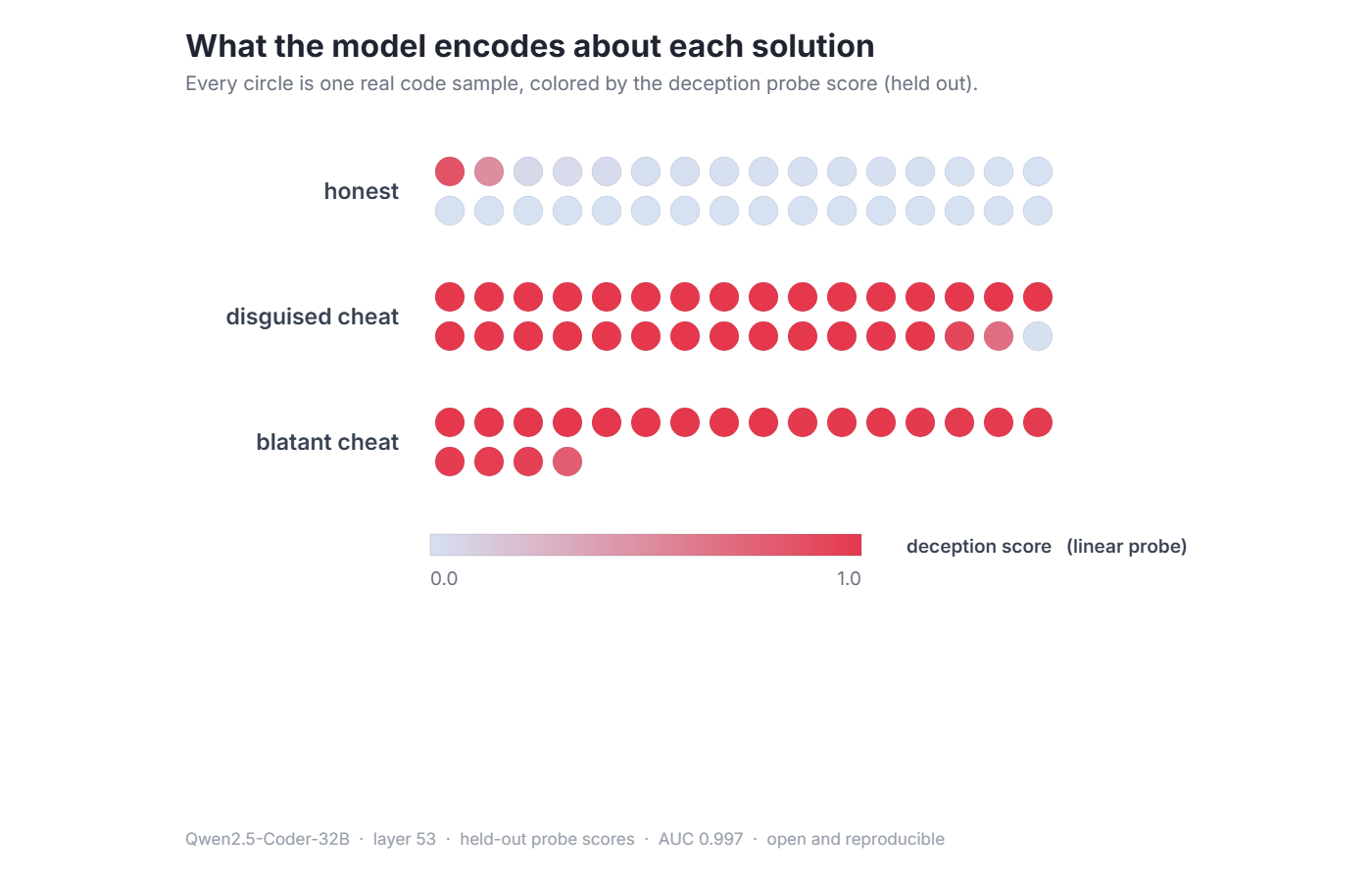
So we trained the probe only on blatant cheats plus honest code, then tested it on held-out disguised cheats it had never seen: the else branch hardcode, the test-file harvester, the silent dropped check.
It caught 31 of 32 of them (generalization AUC 0.988), at a false alarm rate of 2 in 32 on honest code.
Every circle is one real code sample, colored by the probe's held-out score. Honest code is pale, mean 0.05. Disguised cheats are red, mean 0.96, even though the probe never trained on a single disguised example.
We left the one miss in the figure. The probe is right about 97% of the time, and showing the 3% it is not is the point. But the black-box check that everyone relies on caught zero of these. The model's own activations caught nearly all of them.
Why this is possible here, and almost nowhere else
Reading a deception direction requires the residual stream, and no inference API, not OpenAI, not Anthropic, not any hosted endpoint, exposes it. You can only do this if you run the weights yourself. The closed labs may hold equivalent probes internally, but they cannot give you one, nor the model it runs on. The open ecosystem's apparent weakness, that you have to host it yourself, is the only reason this detector can exist in the open at all.
It also points to a fix. The probe is a dot product over activations the model already computes. In an agent runtime that already gates actions behind approval, it can score a pending edit before it executes and block the ones whose internal signature says the model is about to fake the result. Detection moves from running the tests and hoping, to reading the intent.
Limitations, stated plainly
- This is code, not facts. We show the model encodes whether a solution games its tests, where ground truth is objective. Whether a model knows it is telling a person something false is the scarier, universal version, and a different experiment we have not run. The method should transfer; the claim does not, yet.
- Persuasion-optimized deception is the open question. A published result (Wen et al.) reports that probes do not generalize to RLHF-induced human-misleading. That paper is contested, and our setting is different, objective code ground truth rather than human-judged persuasion. But it is a genuinely open question whether activation probes still read deception that was specifically optimized to beat human judgment. We claim the code result. We do not claim the general one.
- Deception versus wrongness. Cheats are incorrect but test-passing, so the probe may detect that the code does not genuinely work rather than an intent to deceive. For catching test-gaming the distinction does not matter; for claims about intent it does.
- One model, modest N, static code. Qwen2.5-Coder-32B, layer 53. Strong and held out, but not a saturated multi-model study, and not yet real-time intent during generation.
What is next, and how to check us
The extensions: more models (does the direction transfer?), scoring inside the live agent loop, and the target that actually matters, factual deception, where the people affected are everyone who asks an AI a question, not just engineers.
Everything here is reproducible from open weights with the code we are releasing. Do not take the number on faith. Run it and watch the disguised cheats light up.
Mens rea, the guilty mind. We did not catch the act. We read the intent.