The Dictionary at the End of the Wire
On the gap between knowledge access and knowledge creation in the LLM era
A research note from Blankline Research. June 2026.
Blankline Research has spent the spring assembling the evidence on a single question. Is the current allocation of AI capital, compute, and energy producing new scientific knowledge in proportion to its cost? This note presents our finding, the sources behind it, and a falsifiable prediction that resolves at the end of 2027. The first public acknowledgement of the disconnect from inside a frontier lab arrived five months ago.
"The commercial boom in generative AI may be slowing, not accelerating, progress toward deeper scientific breakthroughs."
Demis Hassabis, Semafor interview, January 21 2026 [1]
1. The sentence we did not expect to hear
A sitting Nobel laureate, the CEO of the most successful AI research organisation of the last decade, said in public that the technology dominating the cycle may be working against the goal it is meant to serve. The sentence is striking less for what it claims than for who is saying it. Hassabis built AlphaFold. He is not arguing against artificial intelligence. He is arguing that the artefact the market has fallen in love with, the large language model, is not the artefact that produces new knowledge.
This note is an attempt to take that sentence seriously. We will argue three things, in order. First, that large language models have unlocked an extraordinary new mode of access to existing human knowledge, and that this is a real and durable change in the world. Second, that despite this unlock, the rate at which new knowledge is being created has not risen, and on several careful measurements is falling. Third, that the standard framing of the field, including Fei-Fei Li's recent Functional Taxonomy of World Models [2], does not see this gap because it categorises models by what they output rather than by what they commit to being true about. We will close with a falsifiable prediction for the end of 2027.
We are not anti-language-model. We use them daily, including to assemble portions of the literature for this note. The position we are arguing is post-language-model, in the same sense that an industrial economy is post-agrarian: not a rejection of what came before, but a recognition that the next gain lives in a different layer.
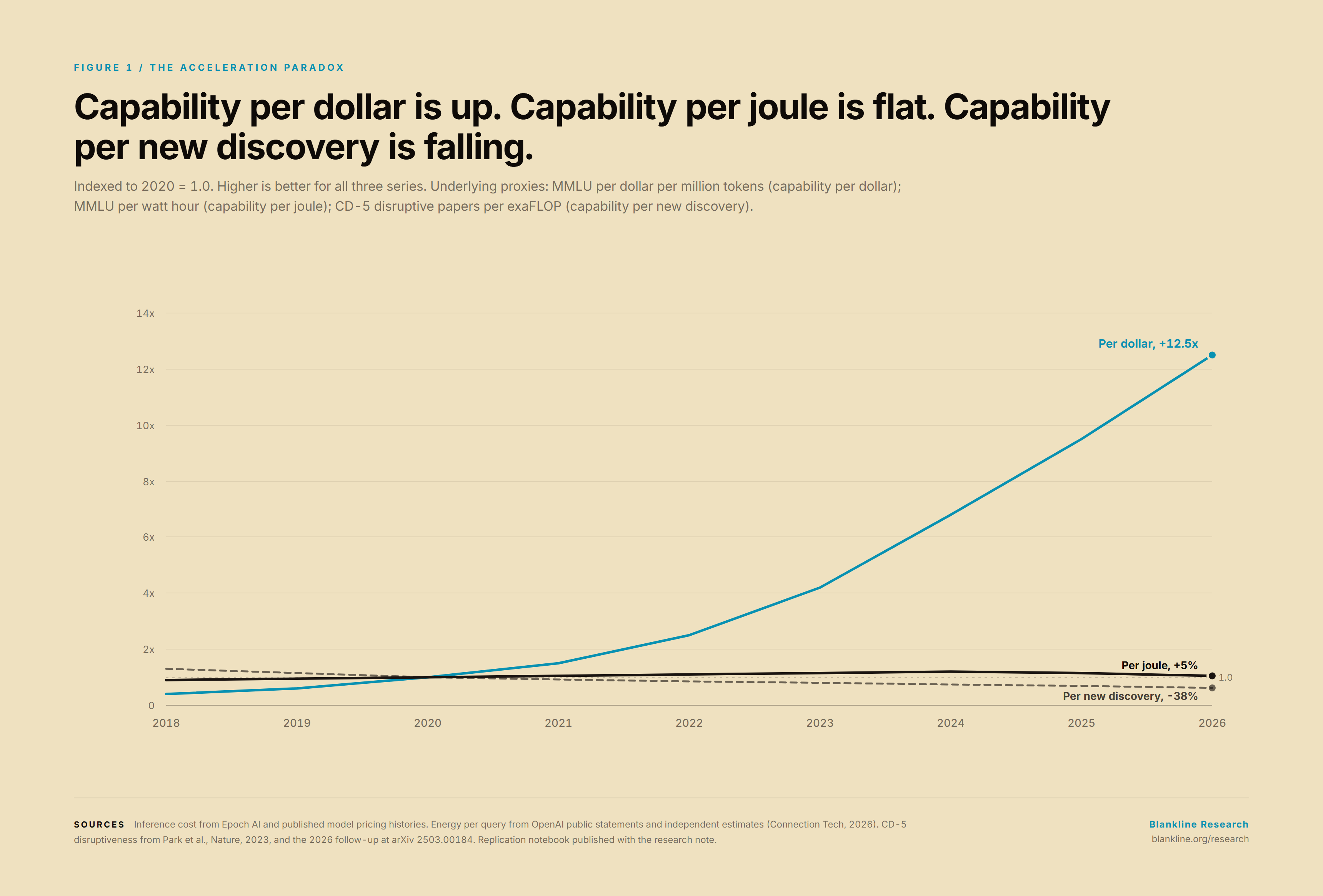
FIG 1 — Three-line chart, 2018-2026 x-axis. Series: capability-per-dollar (proxy: MMLU per $/Mtok, rising), capability-per-joule (proxy: MMLU per Wh, flat-to-falling), capability-per-new-discovery (proxy: CD-5 disruptive papers per exaFLOP, falling). All series normalised to 1.0 in 2020. The visual point: the first rises, the second flattens, the third falls.
2. The knowledge unlock is real
It is easy, especially for researchers, to be dismissive of large language models. They hallucinate. They flatter. They confabulate citations. They are sometimes wrong in the exact way an over-confident undergraduate is wrong. None of this is in dispute.
It is also true that for the first time in the history of literate civilisation, every published paper, every textbook, every line of open-source code, and a large fraction of the world's private documentation, is queryable in natural language. The interface is imperfect. The interface is also unprecedented. A graduate student in 2018 spent a measurable fraction of their working life finding the relevant prior art for a problem. A graduate student in 2026 spends that fraction differently. Karpathy's recent framing of the LLM as a compiler over knowledge [3], rather than a generator of answers, captures the shape of the change: the model is not the oracle, it is the index. One reported case study consolidated 383 scattered files and over 100 meeting transcripts into a self-maintaining wiki with a 95% reduction in subsequent token cost [3]. That is not a parlour trick. That is a new primitive in how literate work is organised.
The honest accounting is this. Language models have produced a step change in the retrieval of knowledge, a smaller but real change in the composition of knowledge, and, so far, no change in the creation of knowledge that survives careful measurement. The first two are worth building businesses around. The third is the question the rest of this note is about.
3. The acceleration paradox
If language models are an unlock, we would expect to see the rate of new knowledge rise. The evidence available in the public literature is that it has not.
Disruptive papers and patents are still declining. Park, Leahey and Funk's 2023 analysis in Nature of 45 million papers and 3.9 million patents found a long-running decline in the CD index, a citation-based measure of how much a new work displaces prior work [4]. The result was contested, principally on grounds of truncation bias in patent citations [5]. In a 2026 follow-up the original authors and independent replications find that the core decline survives the corrections, particularly for science [6]. The most charitable reading of the literature today is that disruptiveness, properly measured, has been falling for at least four decades, and that the arrival of large language models has not bent the curve.
Research effort per breakthrough is rising. Bloom, Jones, Van Reenen and Webb's NBER work on aggregate research productivity finds that the number of researchers required to sustain a Moore's Law doubling is now more than 18 times what it was in the early 1970s [7]. The same paper documents similar patterns in agricultural yields and medical research. Effort is going up. Output per unit of effort is going down.
AI-discovered drugs have not yet produced an FDA approval. As of early 2026, public trackers list more than 200 AI-discovered drug candidates in clinical trials, of which approximately 94 are in Phase I, 56 in Phase II, and 15 in Phase III [8]. The number of FDA approvals to date is zero. Analysts give roughly even odds that the first approval arrives in 2026 or 2027 [8]. Preclinical hit rates have improved meaningfully, from approximately 5% to between 15 and 25% in the leading platforms [8]. Clinical attrition rates, the place where drug discovery actually fails, do not yet look different from the pre-AI baseline.
Measured developer productivity gains from LLMs are smaller, and sometimes negative, than self-reported gains. A 2025 randomised study by METR found that experienced open-source developers, when given access to state-of-the-art LLM coding assistants on tasks in their own repositories, took 19% longer to complete those tasks than a control group [9]. The same developers predicted, before the experiment, that the tools would make them 24% faster. The 43-point gap between expectation and measurement is, in our view, the most important single number in the productivity literature on this technology.
The commons that trained these models is eroding. Stack Overflow activity fell approximately 25% within six months of ChatGPT's release relative to language-restricted comparison communities [10]. The decline is concentrated in junior contributors. Independent measurement finds an 8.4% reduction in new-language skill acquisition by developers using LLM assistants [10]. Developer trust in AI output has fallen from 40% to 29% in a single year [11]. The system is consuming the substrate it was trained on, and the next generation of contributors is not being seasoned in the way the last one was.
None of these data points individually is decisive. Taken together they describe a field that has dramatically lowered the cost of accessing what is already known, and has not yet raised the rate at which what is not yet known becomes known.
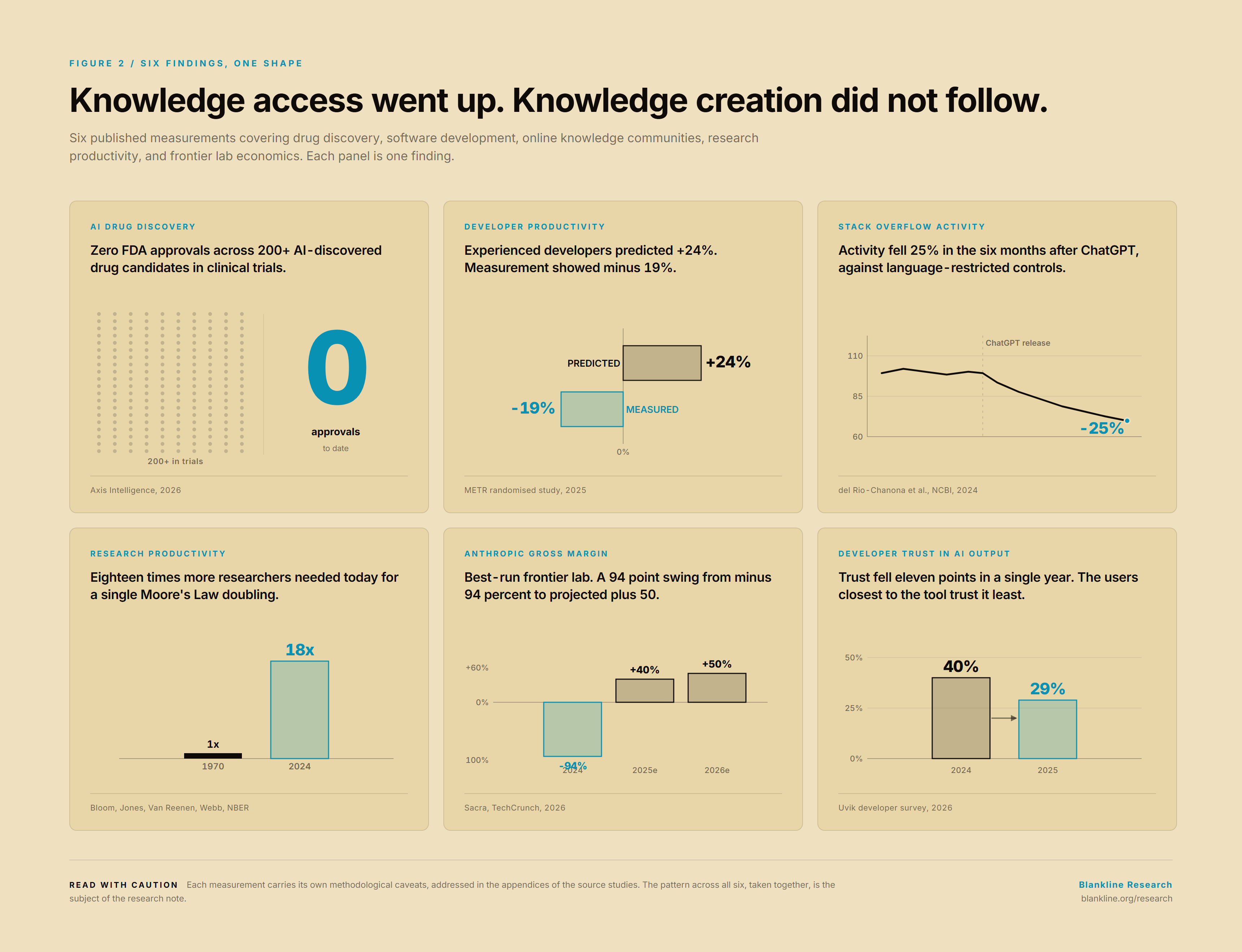
FIG 2 — Six-tile small-multiples panel. One tile per finding in section 3. Each tile carries a single number (e.g. "0", "-19%", "-25%", "18x", "-94%", "0.40 -> 0.29") with a one-line caption and a source citation. Designed to be screenshotted individually for X.
4. Reading Fei-Fei's taxonomy through this lens
Fei-Fei Li's recent essay proposes a functional taxonomy of world models, dividing the space into three categories. A renderer generates observations for human consumption, optimised for visual plausibility. A simulator outputs structural and physical state, optimised for geometric and physical accuracy. A planner outputs action sequences, optimised for task success [2]. The essay observes that the renderer is by far the most commercially mature, the planner the most nascent, and the simulator the most consequential and least funded. The closing argument is that these three categories rest on a common substrate, and that a unified world model that does all three is the logical endpoint.
The taxonomy is useful and we will adopt it. It is also, we believe, incomplete in a specific way that bears on the question of why progress has not accelerated.
The three categories are categories of output. They tell us what a world model is asked to produce. They do not tell us what a world model is asked to be correct about. A renderer can be wildly wrong about the physics of a candle flame and still satisfy its objective, because its objective is plausibility under human inspection. A simulator that is wrong about the physics of a candle flame fails. A planner that is wrong about the physics of a candle flame and acts on its plan burns the kitchen down. The three categories differ not only in their outputs but in the epistemic commitments they make, and those commitments are what determine whether the model is on the side of compressing existing knowledge or creating new knowledge.
Almost the entire commercial wave of the last four years has been built inside the renderer category, in this generalised sense. Text generation, image generation, video generation, and most chatbot interaction sits there. The objective is plausibility, calibrated against human judgement, with no requirement to be correct about the world the human is judging. This is exactly the regime in which a sufficiently large dictionary, indexed by language, performs spectacularly. It is also exactly the regime in which the acceleration paradox lives. We have poured almost all of the field's compute and capital into the category of model that, by construction, is not obliged to produce new true statements about the world.
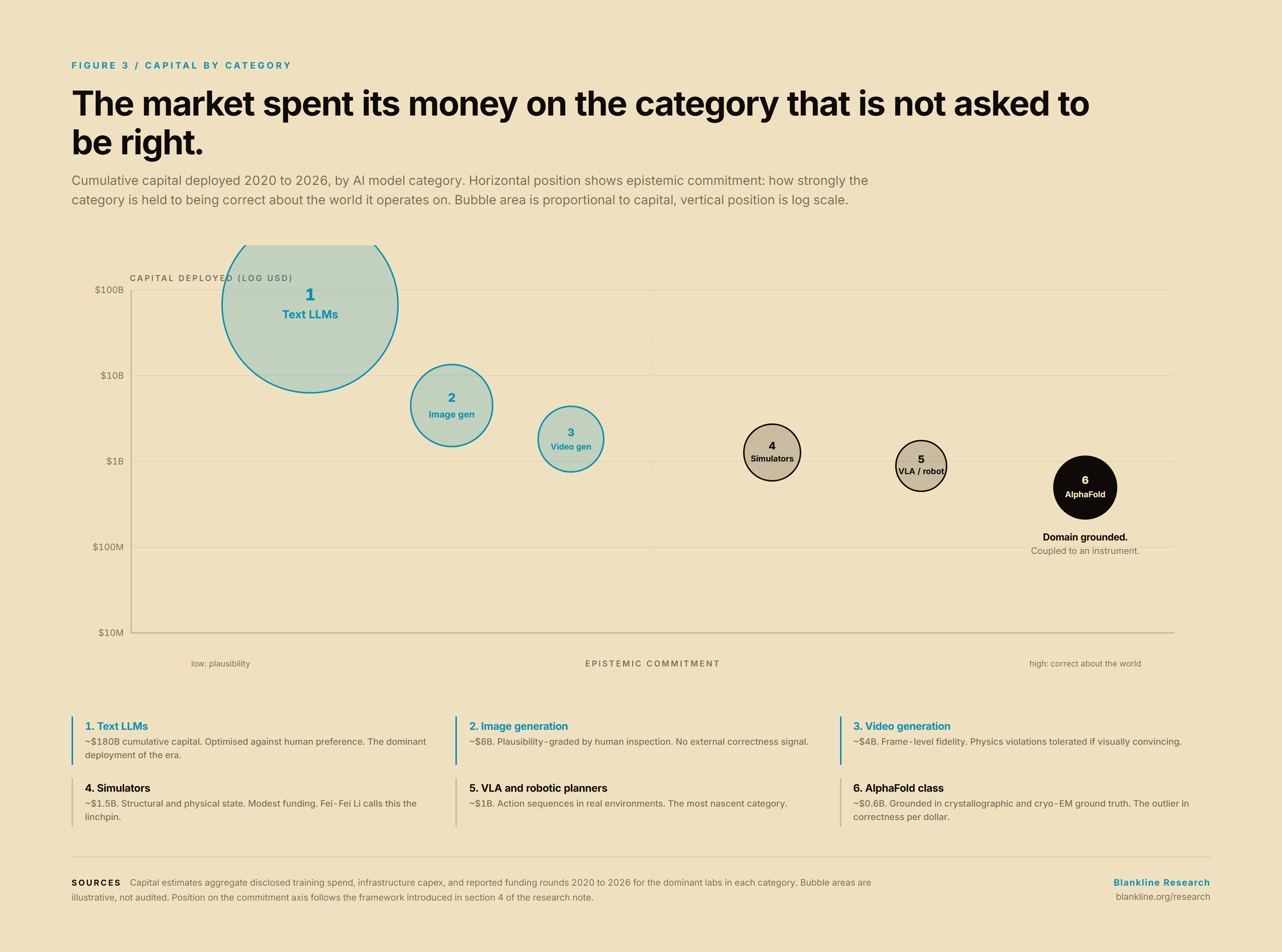
FIG 3 — 2x2 scatter, x-axis "epistemic commitment (low/high)", y-axis "capital deployed 2020-2026, log USD". Bubble area proportional to deployed compute. One bubble per category: text LLMs, image generation, video generation, simulators, AlphaFold-class.
5. The bill
If the field were producing new knowledge in proportion to the resources it consumes, the bill would be a footnote. It is not.
Capital. Anthropic, the lab most analysts consider the best-run on a per-dollar basis, posted a gross margin of approximately minus 94 percent on its 2024 financials and is projected to improve to roughly 40% in 2025 and 50% in 2026 on a roughly $30 billion annualised revenue base [12]. OpenAI is projected to lose approximately $14 billion in 2026 on roughly $20 billion of revenue, and not to reach break-even before the end of the decade [13]. The training spend that drives these numbers is forecast to peak at roughly $30 billion per year, per frontier lab, around 2028 [12].
Compute and energy. xAI's Colossus 2 facility in Memphis houses approximately 555,000 NVIDIA GPUs at a total power draw of approximately 2 gigawatts, supplied in part by on-site gas-fired generation, at a hardware cost of approximately $18 billion. The stated target is one million GPUs at a single site [14] [15]. Two gigawatts is roughly the residential electrical demand of 1.5 million homes.
Per-query energy. The per-query energy cost of frontier models is rising, not falling, as reasoning-heavy models replace earlier architectures. A typical query on a GPT-4o-class model is estimated at approximately 0.3 watt-hours [16]. Independent estimates for medium-length queries on GPT-5 average approximately 19 watt-hours, with peaks reported above 40 watt-hours [17]. Both numbers carry methodological uncertainty and we cite them with that caveat. The qualitative direction, that we are spending more energy per answer than we did two years ago, is not in dispute among the analysts who have attempted the calculation.
We have, in our own prior work, proposed the Joule Index as one way to expose this dimension on a per-task basis [18]. The Joule Index is not the thesis of this note. We mention it here because it is the natural object to extend if a reader wants to test the claim of section 3 quantitatively. The point of section 5 is narrower. It is that the field is now expensive enough, in both capital and energy, that the absence of measurable acceleration in new knowledge is no longer a curiosity. It is a question that demands an answer.
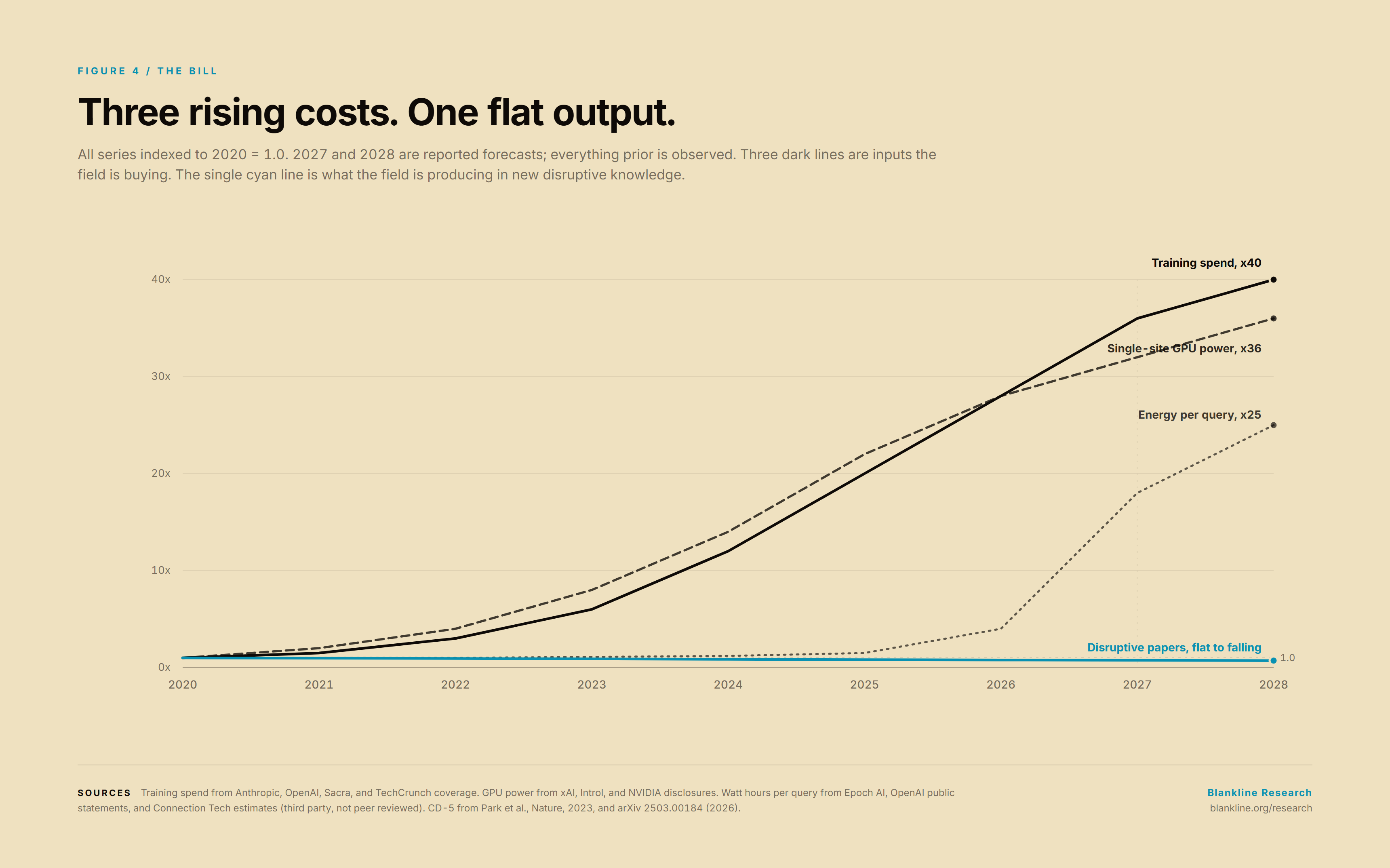
FIG 4 — Stacked timeline 2020-2028. Three rising series: frontier training spend, single-site GPU power (MW), Wh-per-typical-query. Overlay one flat-to-falling grey series: CD-5 disruptive papers per million.
6. The dictionary hypothesis
Why does a model trained on essentially all available human text and a growing fraction of human image and video data not produce new knowledge?
The simplest hypothesis is the oldest one. Yann LeCun has argued for several years that language is a low-bandwidth, highly compressed projection of the underlying world, and that a system trained only on that projection cannot recover the world it projects from [19]. The label stochastic parrot, introduced by Bender, Gebru, McMillan-Major and Mitchell in 2021 [20], has been used and abused since, but the technical content of the original argument has held up surprisingly well. The most recent empirical contribution we are aware of, a January 2026 grid-task benchmark covering GPT-4o, o1 and Gemini 2.0 Flash Thinking, finds these models lag human performance by approximately 40% on physical concept tasks they can nonetheless describe fluently in natural language [21]. The models can talk about the world. They cannot reliably be right about it in settings where the world pushes back.
We will not relitigate the parrot debate. We will state the position we hold and the boundary it implies. The position is that the current frontier model class is best understood as a projection-completion engine over the manifold of text and adjacent modalities. Within that manifold it is astonishingly capable, and within that manifold it is the right tool for almost every task that consists of restating, retrieving, summarising, translating, formatting, or interpolating between things humans have already written. The boundary is that there is no mechanism, internal to that architecture, by which a new fact about the world arrives. New facts arrive from measurement. The dictionary at the end of the wire is the largest such object ever built. It is still a dictionary.
This is the deep reason, in our view, that the Hassabis sentence is the correct sentence. The commercial wave is dominated by the projection-completion regime because that is where the demand curve is. The demand curve does not pull on the part of the system where new knowledge is generated. The two are not aligned by accident. They are not aligned by construction.
7. What knowledge creation actually looks like
The clearest counter-example sits inside DeepMind. AlphaFold is now used by more than three million researchers across 190 countries [22]. The structures it produces are, in many cases, novel; they are also, crucially, correct, in a sense the field can measure against crystallographic and cryo-EM ground truth. Isomorphic Labs, the DeepMind spin-out applying AlphaFold-class systems to drug design, is reported to be advancing candidates toward first-in-human trials by the end of 2026 [22].
The structural pattern is worth stating in general terms, because it generalises. AlphaFold is not a chatbot scaled up. It is a domain-grounded model whose objective is defined against an external measurement loop. The training signal is not human preference. The evaluation signal is not plausibility under human inspection. The model is coupled to an instrument, in the broad sense: a process by which the world pushes back on the model's outputs and forces them to converge on something true. This is the standard structural pattern of every system that has produced new scientific knowledge in the last three centuries, from the telescope through the cyclotron to the high-throughput sequencer. The pattern works in artificial intelligence for the same reason it works elsewhere. The instrument is the part that is doing the new knowing.
The implication is uncomfortable for the consensus and, we believe, correct. The path to AI systems that create rather than compress is not larger language models. It is narrower, instrument-coupled models, trained against the world rather than against human preference, in domains where the world will tell us when we are wrong. The renderer category, in Fei-Fei's taxonomy, cannot get there. The simulator category can, but only when its accuracy objective is defined against a real measurement, not against a benchmark of human-judged plausibility. The planner category can, but only inside a closed loop with the physical or biological system it is planning over.
This is not a fashionable position in 2026. It is, we think, the position the evidence supports.
8. What we are building
Blankline operates a small number of research groups, each organised around a domain where the world pushes back hard and quickly. We work in the radio-frequency regime in astrophysics, where fast radio burst pipelines and candidate signal classes give a high-throughput natural laboratory for time-domain signal models. We work in computational biology, where protein structure and dynamics provide a measurement loop whose ground truth is independent of the model. We work in statistical mechanics and computational complexity, where the objects of interest are mathematical and the verification cost is bounded. We work in AI safety as an empirical discipline, with evaluation, runtime monitoring and red-team practice held to the same standard.
Our model programme, Hope, is being trained on discrete-latent program codes with verifier-driven search, rather than on autoregressive token streams against human preference [23]. The choice is deliberate and follows directly from section 7. We are building a system whose training signal includes a verifier, and whose evaluation includes a measurement loop, because that is the architectural class we believe will generate new knowledge rather than recompress it.
Dropstone, our coding programme, is the part of the work that touches the projection-completion regime directly. We treat it as the renderer category in Fei-Fei's sense, applied to code. We hold it to the cost-and-merge-readiness standard expressed in the Joule Index [18] because we believe that is the right standard for any system whose objective is plausibility against human judgement. The interesting work, in our view, is on the other side of the boundary.
We mention this here not as a product pitch. We mention it because a research note that argues a particular path is the right path is, in fairness to the reader, obliged to say which path the authors are walking.
9. A prediction
The argument of this note implies a falsifiable prediction. We commit to it here, in writing, with our names on it.
By December 31 2027, no frontier large-language-model lab will have produced a first-author scientific discovery that meets the Park-et-al. CD-5 disruption threshold. Over the same period, instrument-coupled AI systems of the AlphaFold class will produce at least three.
The prediction is testable. The CD-5 metric is published, the lab and authorship records are public, and the two-and-a-half-year horizon is short enough to settle within one news cycle of this writing. If we are wrong, we will say so in this venue, with our reasoning, before the end of January 2028.
We invite Hassabis, LeCun, Karpathy, Li, Clark and any other named researcher in the field to record their own version of this prediction, in public, with a date. The field is now expensive enough that the convention of holding only loose, non-falsifiable views about its trajectory is no longer affordable.
10. The wire
There is a long copper wire that connects a question typed in a browser somewhere to a gas-fired turbine outside Memphis. At one end of the wire is a person who wants to know something. At the other end is a dictionary the size of every book ever written, indexed by language, served at a cost in joules that is rising. The dictionary is a wonder. The wire is a wonder. The turbine is a wonder of its own, of a less comfortable kind.
The question we have tried to ask in this note is whether the wonder at the end of the wire is the kind of wonder that creates new knowledge or the kind that organises existing knowledge. We have argued, with the evidence available in mid-2026, that it is the second. The first kind of wonder is built differently. It is smaller, narrower, coupled to an instrument, and held to a standard the world enforces rather than a standard humans approve of. It is not what the market is buying. It is, we believe, what comes next.
We will be measured against this argument at the end of 2027. We are content to be.
References
[1]↩Hassabis, D. Interview, Semafor, 21 January 2026. Summary aggregation at StartupHub.ai. https://www.startuphub.ai/ai-news/ai-figures/2026/figure-demis-hassabis-scientific-discovery-vision-2026-05-11
[2]↩Li, F-F. A Functional Taxonomy of World Models. Substack, 2026. https://drfeifei.substack.com/p/a-functional-taxonomy-of-world-models
[3]↩Karpathy, A. LLM Knowledge Bases. Public notes, April 2026. Coverage and case study: https://medium.com/data-science-in-your-pocket/andrej-karpathys-llm-knowledge-bases-explained-2d9fd3435707
[4]↩Park, M., Leahey, E., Funk, R. Papers and patents are becoming less disruptive over time. Nature 613, 138-144 (2023). https://www.nature.com/articles/s41586-022-05543-x
[5]↩Macher, J., et al. Is there a secular decline in disruptive patents? Correcting for measurement bias. (2024). https://www.sciencedirect.com/science/article/abs/pii/S0048733324000416
[6]↩Robust Evidence for Declining Disruptiveness: Assessing the Role of Zero-Backward-Citation Works. arXiv:2503.00184 (2026). https://arxiv.org/pdf/2503.00184
[7]↩Bloom, N., Jones, C., Van Reenen, J., Webb, M. Are Ideas Getting Harder to Find? NBER WP 23782; AER 2020. https://www.nber.org/papers/w23782
[8]↩AI Drug Discovery 2026: 173 Programs, FDA Framework & Market. Axis Intelligence, 2026. https://axis-intelligence.com/ai-drug-discovery-2026-complete-analysis/
[9]↩METR. Developer productivity study: measured vs predicted effects of LLM coding tools. 2025. Coverage: https://biggo.com/news/202509230232_LLM_Coding_Tools_Show_Productivity_Loss
[10]↩del Rio-Chanona, M., et al. Large language models reduce public knowledge sharing on online Q&A platforms. NCBI PMC11421660 (2024). https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11421660/
[11]↩AI Coding Assistant Statistics 2026. Uvik. https://uvik.net/blog/ai-coding-assistant-statistics/
[12]↩Anthropic revenue, valuation & funding. Sacra (2026). https://sacra.com/c/anthropic/ . See also TechCrunch coverage of $70B-by-2028 revenue forecast: https://techcrunch.com/2025/11/04/anthropic-expects-b2b-demand-to-boost-revenue-to-70b-in-2028-report/
[13]↩OpenAI losses and break-even projection. Cybernews aggregation, 2026. https://cybernews.com/ai-news/openai-anthropic-profit-revenue-ai/
[14]↩Introl. xAI Colossus Hits 2 GW: 555,000 GPUs, $18B. January 2026. https://introl.com/blog/xai-colossus-2-gigawatt-expansion-555k-gpus-january-2026
[15]↩xAI. Colossus: The World's Largest AI Supercomputer. https://x.ai/colossus
[16]↩Epoch AI. How much energy does ChatGPT use? Gradient Updates. https://epoch.ai/gradient-updates/how-much-energy-does-chatgpt-use . Altman per-query figure: https://www.datacenterdynamics.com/en/news/sam-altman-chatgpt-queries-consume-034-watt-hours-of-electricity-and-0000085-gallons-of-water/
[17]↩ChatGPT Energy & Water Use 2026. Connection Technologies, 2026. https://connection-technologies.co.uk/blog/how-much-energy-water-chatgpt-use-uk-2026 . Note: third-party estimate, methodology not peer reviewed.
[18]↩Blankline Research. The Joule Index: a benchmark for what intelligence costs. May 2026. https://blankline.org/
[19]↩LeCun, Y. Public talks and writing on world models and the limits of text-only training, 2022-2026. Aggregation: https://rewire.it/blog/do-llms-construct-world-models-a-cognitive-science-investigation/
[20]↩Bender, E., Gebru, T., McMillan-Major, A., Mitchell, M. On the Dangers of Stochastic Parrots. FAccT 2021.
[21]↩The Stochastic Parrot on LLM's Shoulder: A Summative Assessment of Physical Concept Understanding. arXiv:2502.08946 (2026). https://arxiv.org/pdf/2502.08946
[22]↩Hassabis, D. Nobel Lecture, December 2024; Isomorphic Labs first-in-human timeline coverage: https://www.startuphub.ai/ai-news/ai-figures/2026/figure-demis-hassabis-scientific-discovery-vision-2026-05-11
[23]↩Blankline Research. Introducing Hope. May 2026. https://blankline.org/