The Economics of Intelligence
Where the cost of reasoning can be reduced, where it cannot, and what that means for how to build.
Modern language models are extraordinary, and extraordinarily expensive. DeepSeek-V3 reached the frontier for a reported ~$5.6M of training; GPT- and Claude-class runs cost tens to hundreds of millions. As those numbers became the story, a belief took hold across the field: that intelligence-per-dollar is the next moat — whoever computes reasoning most cheaply wins.
We spent a staged, low-cost research program testing the strongest version of that belief: that a from-scratch architecture could deliver frontier-level reasoning at a fraction of the cost, not a 2× engineering saving but a different way of computing that moves intelligence-per-dollar by an order of magnitude. This post reports what we found.
We find the opposite of the prevailing belief. The levers that lower the cost of reasoning are real, but they are bounded and largely copyable, which makes them a cost frontier the whole field shares rather than a private advantage. General intelligence remains capacity-bound. The reachable, defensible target for a small lab is not a cheaper general intelligence but the cheapest dependable reasoner on verifiable tasks — and that is why we build a runtime on open weights rather than a foundation model.
Decomposing the cost of intelligence
We wanted a way to test an expensive idea cheaply, so we began by writing the cost of reaching the frontier as a product of four terms:
cost-to-frontier ≈ (information to absorb) × (FLOPs per bit) × (price per FLOP) × (passes) ÷ (parallel efficiency)
Three of these — price-per-FLOP, passes, and parallel efficiency — are silicon and systems. They are already heavily optimized, and improving them yields a bounded constant factor. Only FLOPs-per-bit-absorbed is algorithmic, and it is the only term where an architecture could, in principle, move intelligence-per-dollar by 100×. So that is the term we studied, through structured latent representations, recurrence, sparse memory, and test-time computation.
Every decisive experiment ran on a single consumer GPU or free cloud hardware, under one rule: we would not commit money or scale until a cheap experiment showed the edge existed and grew. The whole program cost about $1.50 in compute.
A tour of the efficiency levers
Compressing context lowers the per-FLOP cost
Matched on parameters and data against a plain transformer on abstract reasoning (ARC), a structured-latent model reached 93% of the transformer's accuracy using 21.6% of the FLOPs — a 4.3× per-FLOP advantage.
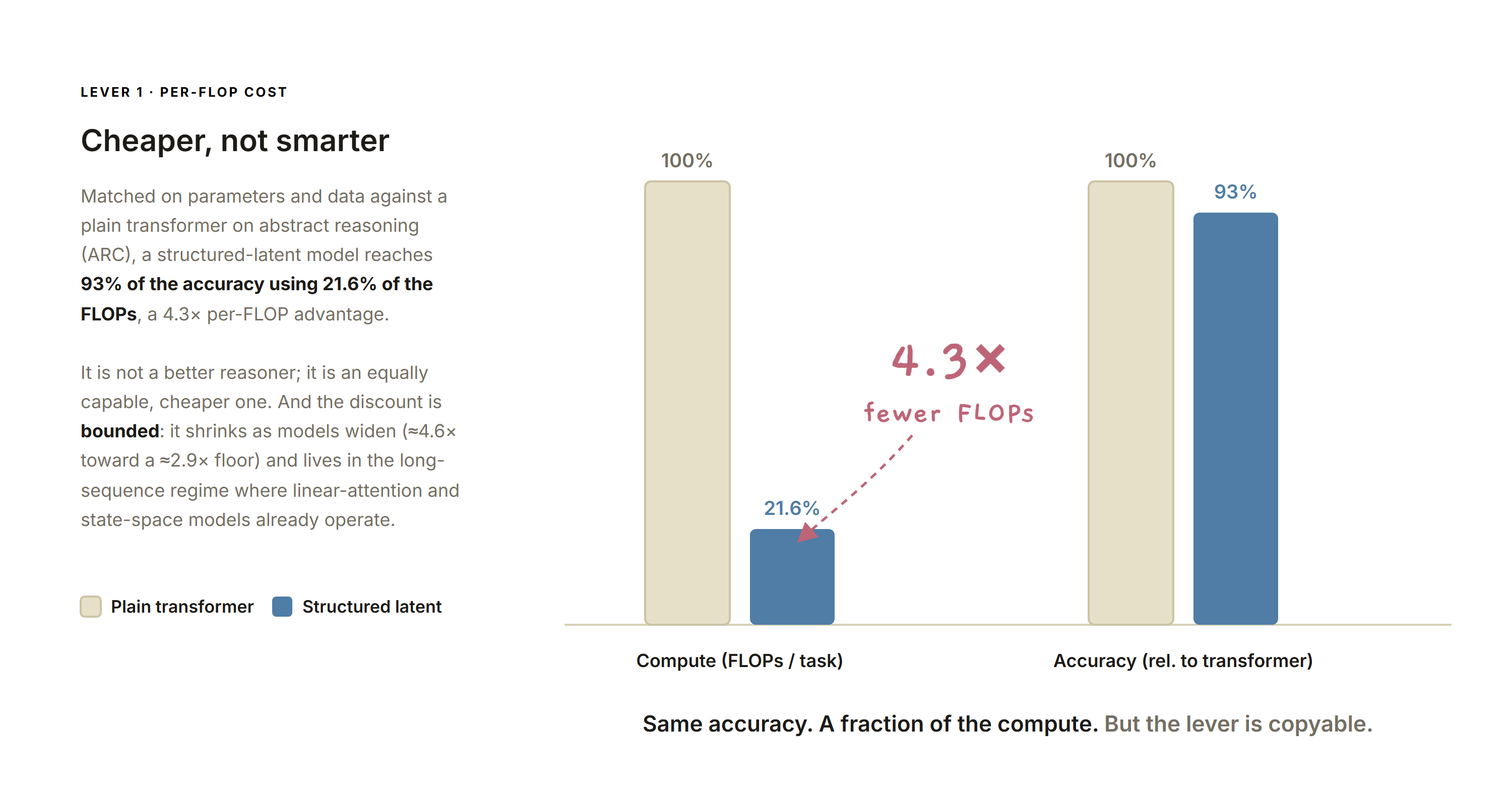
Structured latent vs. plain transformer at matched compute: same accuracy, a fraction of the FLOPs.
It is not a better reasoner; on raw accuracy the transformer is marginally ahead. It is an equally capable, cheaper one. And the discount is bounded: it comes from compressing a long context into a short latent, so it shrinks as models widen (from ~4.6× toward a ~2.9× floor) and grows only on long sequences — the same regime where linear-attention and state-space models already operate. The lever is real, and it is not unique to us.
Separating storage from reasoning
Width in a dense network does two jobs: it stores knowledge, and it provides reasoning bandwidth. We find that these come apart. Storage offloads to a sparse memory — a small core plus memory matched a model with 44× more compute parameters on a recall task. Reasoning depth comes from recurrence — a looped small core extrapolated a reasoning task to twice its trained depth where stacked layers failed, at 11× fewer parameters.
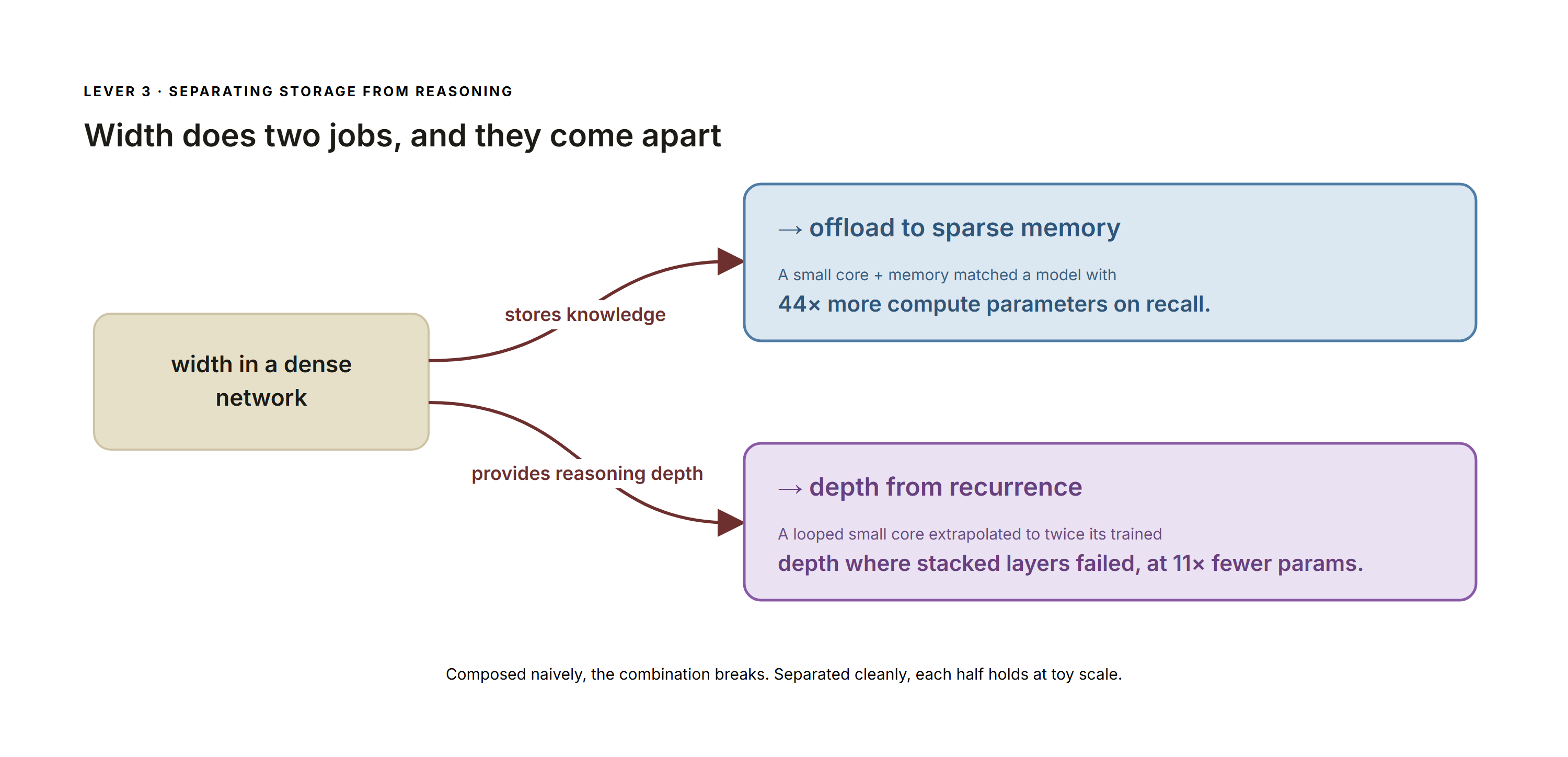
Width does two jobs; storage offloads to sparse memory and depth comes from recurrence.
Both results are at toy scale, and the composition is fragile. A memory lookup placed inside the reasoning loop did not generalize to states it never indexed, and depth-extrapolation collapsed. The corrected, separated design works, but modestly: on the official ARC evaluation subset it reached ~9%, above a matched dense baseline and below the cheap state of the art.
Adapting weights at test time
The most effective method we found was not an architecture but a procedure: test-time training, adapting a model's weights to each individual problem before answering. A frozen 1.3M-parameter model scored ~0% on the official ARC evaluation subset; the same model with per-task adaptation reached ~16.7%, for a few cents of compute.
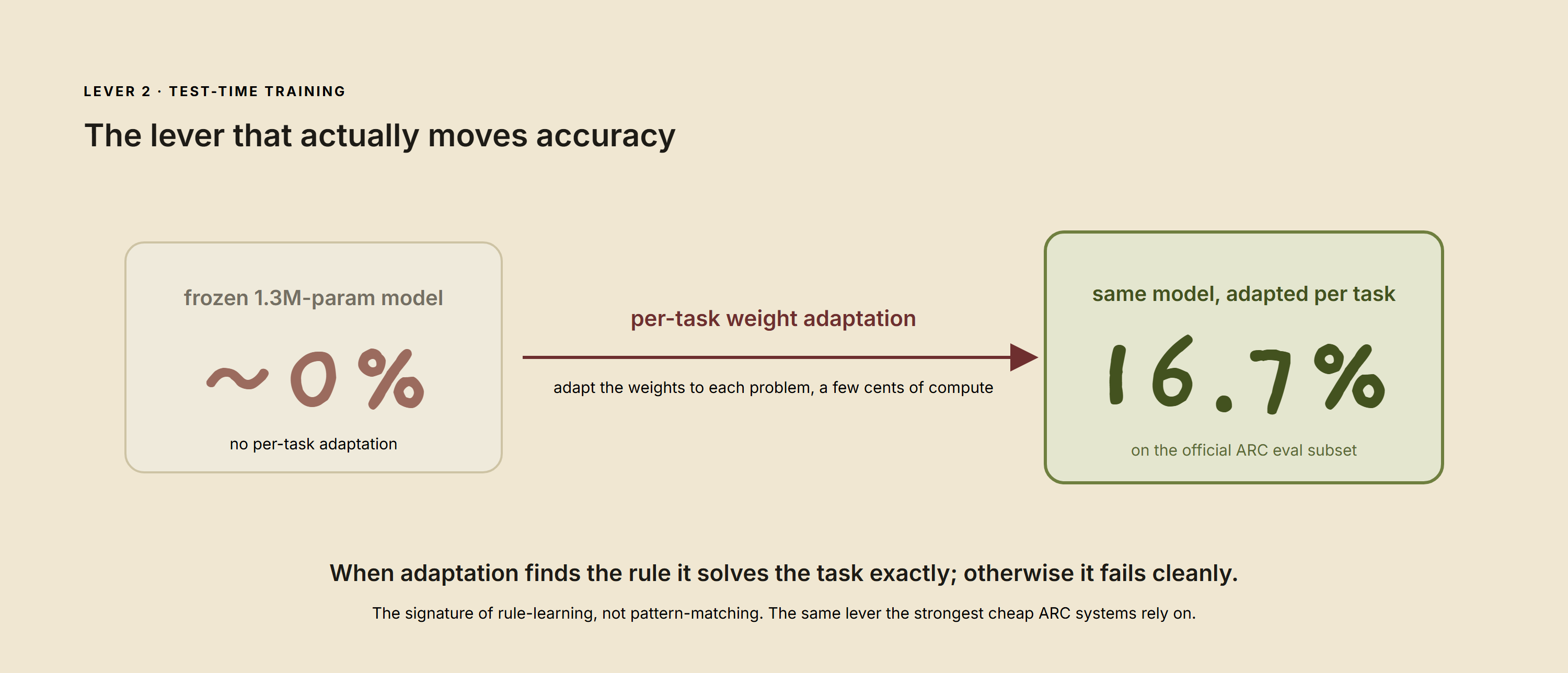
A frozen model scores near zero; per-task weight adaptation lifts it to 16.7%.
When the adaptation finds the rule it solves the problem exactly, and otherwise fails cleanly — closer to rule-learning than pattern-matching. The strongest cheap ARC systems rely on the same lever.
Verifiable reasoning on commodity hardware
A 1.5B open model with self-consistency voting reached 86% on GSM8K for about $0.16 per fifty problems on a consumer GPU, within range of frontier systems on verifiable math. None of this is novel: it is an open model, a standard technique, and commodity inference. We report it because it establishes the premise the rest of the work builds on. Cheap, verifiable reasoning is reproducible today.
Where the levers stop compounding
The levers above are genuine. The levers that would compound — the path toward 100× — are the ones we could not get to form.
Does in-context inference form at small scale?
Latent search, self-improvement, and compounding all depend on one capability: inferring a rule from a few examples. We tested this directly, with forced inference, unlimited data, and long training, from 1.5M to 43M parameters, for the structured-latent model and for a plain transformer. Neither learned to infer. Both could apply a known transformation perfectly, but neither learned to read a new rule from demonstrations. This is consistent with the literature: in-context learning is a property of large autoregressive models and emerges around the ~10B-parameter scale. It appears to be a scale property, not a tuning one.
Does self-improvement compound?
A verifier-closed self-improvement loop is the one mechanism that could produce capability beyond the training data. We tested it four mechanistically distinct ways. Each produced a small initial gain and then flat-lined, matching the broader finding that reinforcement learning from verifiable rewards compounds on competent multi-billion-parameter bases, not on sub-million-parameter models.
The limits of cheap test-time compute
Stacking more adaptation, voting, and the equivariance and compression priors that other cheap systems use moved the ARC result only marginally before plateauing. The remaining failures are capability gaps — object perception, larger grids — that aggregation does not address.
Caveats
Every positive result above is at toy scale on structured tasks. The cost figures are real; the capability figures sit below the cheap state of the art (CompressARC ~20%, TRM ~45% on full ARC-AGI-1). Two directions we have not yet tested — continual-learning memory and an integrated self-improvement loop — are hypotheses, not results, and validating them requires scale we have not yet reached.
What the results imply
Together the results form a map.

The levers are real but bounded and copyable; the wall is capacity; the edge is not ownable.
General intelligence appears capacity-bound: reasoning breadth and reliability scale with capacity, and we found no sign of a cheap model that generally out-reasons the frontier. Intelligence-per-dollar does improve, but through bounded, composable, and largely copyable levers — sequence compression, sparse activation, separated memory, recurrence, test-time computation. Stacked, they are a real path to an order of magnitude of efficiency. They make a lab an efficient challenger, not a frontier-beater.
The reachable, defensible target is therefore the cheapest system that reasons at frontier level on verifiable, structured tasks — math, code, and domains where a checker exists. That is provable and buildable. "Generally smarter than the frontier, cheaply" is not.
Building Dropstone on the conclusion
If algorithmic efficiency were a moat, the right move for a small lab would be to race for it. Our results suggest it is not: efficiency diffuses, and capacity still sets the ceiling. That changes the rational strategy. Rather than spend tens of millions training a model the field would soon copy, the move is to take the best available open weights and compete where the advantage is durable — runtime, evaluation, safety, and cost.
Dropstone is built on exactly that conclusion. It is not a foundation model. It is an agentic coding runtime that runs on the strongest open-weight frontier models, re-evaluated on a public eval harness each release, with safety, security, and cost as the product. Coding is where it is anchored, on the verifiable, checkable tasks the research points to, and it is now expanding from there into a more general agentic app on the same foundation. The research is the reason it takes this shape.
We will continue to publish what we find, including what fails.
Appendix: results summary
| Stage | What it tested | Result |
|---|---|---|
| Structured latent + search | does a discrete program latent help | holds, toy scale |
| Per-FLOP comparison | structured latent vs transformer, matched compute | 4.3× cheaper, equal accuracy; bounded |
| Test-time training | per-task weight adaptation on ARC | ~16.7% on the ≤10 eval subset, cents of compute |
| Separated core | offload storage, recurse reasoning | both hold at toy scale; assembly modest (~9%) |
| Self-improvement | does experience compound | no compounding at small scale |
| In-context inference | infer a rule from examples | does not form below ~10B (structured-latent model and plain transformer alike) |
| Scale | the efficient challenger at scale | not reached; requires resources beyond a single GPU |