.jpg&w=3840&q=75)
Introduction
Today, we publicly release our research on the D3 Adaptive Memory Architecture—a system that fundamentally reimagines how AI coding assistants remember and retrieve information from your codebase. Our work addresses a critical failure mode that affects every major AI coding tool on the market, from Cursor to GitHub Copilot to Claude Code.
The problem is deceptively simple: your AI assistant is forgetting your code.
Not immediately. Not obviously. But steadily, silently, and systematically. Information older than a few months effectively vanishes from the AI's accessible memory, regardless of how important it might be to your current task. We call this phenomenon the Temporal Event Horizon, and solving it required us to rethink retrieval-augmented generation from first principles.
The results speak for themselves: D3 achieves 88.7% recall on legacy code (older than 6 months) compared to just 12.4% for existing approaches—a 7× improvement that transforms AI assistants from tools that only understand your recent work into true long-term coding partners.
This blog post explains what we discovered, why it matters, and how we fixed it.
The Hidden Failure Mode in Every AI Coding Tool
The Promise of RAG
Retrieval-Augmented Generation (RAG) was supposed to solve the context problem. Instead of forcing everything into the model's limited context window, RAG systems index your codebase, search for relevant chunks when you ask a question, and inject only what's needed into the prompt.
It is an elegant architecture. It is computationally efficient. And it is fundamentally broken for long-running projects.
To understand why, we need to examine what happens under the hood when you ask your AI assistant about code that was written months or years ago.
The Experiment That Revealed the Problem
We constructed a controlled experiment using a synthetic codebase designed to stress-test long-range retrieval. The corpus contained 1 million tokens spanning 2 years of simulated development history, with documents uniformly distributed across the timeline.
We then ran 1,000 queries, half targeting recent code (modified within 30 days) and half targeting legacy code (created 6–24 months prior). Each query had a known ground-truth answer.
The results were stark:

For recent code, the system performed excellently. For legacy code, it failed catastrophically. Nearly 88% of relevant historical documents were never surfaced to the model. This wasn't a bug in our implementation; this is how RAG systems are designed to work.
Exponential Decay: The Mathematical Root Cause
The culprit is a seemingly innocuous design decision: temporal decay.
RAG systems do not treat all documents equally. They apply a recency bias, assuming that recently modified files are more likely to be relevant than older ones. This is implemented as an exponential decay function:
Where is the age of the document in hours and is a decay constant (typically around 0.001).
For recent documents, this works fine. But watch what happens as time increases:
- 1 week old: Score = 0.845
- 3 months old: Score = 0.115
- 1 year old: Score = 0.00017
- 2 years old: Score = 0.000000024
A document that is 2 years old receives a recency score of essentially zero. Even if it is a perfect semantic match for your query, that score gets multiplied into the final ranking, effectively eliminating the document from consideration.
We call this the Temporal Event Horizon: a threshold beyond which information cannot escape, no matter how relevant it is.
Why This Matters More Than You Think
"But I mostly work with recent code anyway," you might think. This is a dangerous assumption for several reasons:
- Configuration and Infrastructure: Your database connection strings and environment configurations were likely written months or years ago. Losing this context leads to suggestions that conflict with your architecture.
- Architectural Decisions: The "why" behind your code—framework choices, data flow, module communication—is encoded in the project's inception.
- Utility Functions: Stable, mature helpers (date formatting, validation) become invisible precisely because they rarely need modification.
- Bug Fix History: If the AI cannot see a race condition you fixed 8 months ago, it might suggest "improvements" that reintroduce the exact bug you already solved.
Why Existing Tools Don't Solve This
Cursor's Approach
Cursor has become the benchmark for AI-assisted coding. However, our experiments suggest it uses a standard vector similarity approach with recency bias. In our benchmarks, a RAG system mimicking this architecture achieved only 12.4% recall on legacy code. It lacks temporal modeling, supersession tracking, and formal retrieval guarantees.
GitHub Copilot's Limitations
Copilot relies primarily on immediate file context and recent editor history. It is not designed for cross-file retrieval in long-running projects with years of history.
Claude Code and Context Stuffing
Anthropic's approach uses the model's massive context window (200K tokens) to fit the code directly in the prompt. While this solves the temporal problem, it introduces new ones:
- Quadratic Cost: Transformer attention scales as .
- Cost Efficiency: For a million-token codebase, context stuffing costs ~$5 per query. D3 achieves comparable recall at **$0.007 per query**—a 700× reduction.
The Common Thread
Every existing tool treats retrieval as a search problem (like Google). D3 reframes retrieval as a memory problem (like a human brain). This shift in perspective led us to the solution.
The D3 Solution—Treating Retrieval as Memory
Inspiration from Cognitive Science
Human memory works via the Atkinson-Shiffrin model (1968): information flows from sensory to short-term to long-term memory. Critically, long-term memories don't disappear; they just become less accessible. D3 implements this distinction between availability (storage) and accessibility (retrieval) computationally.
The D3 Memory Hierarchy
Instead of a flat index, D3 organizes memories into tiers:
- Working Memory ( hour): Currently active files (Confidence: 1.0)
- Short-Term Memory ( hours): Files accessed today (Confidence: 0.95)
- Episodic Memory ( days): Sprint-related code (Confidence: 0.9)
- Long-Term Memory ( days): Historical codebase (Confidence: , but never below floor)
The Logarithmic Floor
The key innovation that solves the Temporal Event Horizon is the Logarithmic Floor. Instead of allowing temporal scores to decay to zero, we enforce a minimum based on corpus size ():
For a codebase of 1 million tokens, the floor is . This means even a 10-year-old document can be retrieved if its semantic similarity exceeds this low bar. The logarithmic function naturally adapts to scale while maintaining the guarantee that relevant historical code is always retrievable.
Multi-Signal Fusion
Standard RAG relies solely on vector similarity (). D3 fuses three orthogonal signals:
- Semantic Similarity: Captures conceptual relevance.
- Lexical Matching (FTS5 BM25): Captures exact identifiers (e.g.,
handleAuthCallback) that vectors often miss. - Temporal Recency: Captures natural relevance while maintaining the floor.
These are combined using Reciprocal Rank Fusion (RRF):
Supersession-Aware Retrieval
D3 tracks when new code explicitly updates old facts (e.g., rotating an API key).
SQL
CREATE TABLE memory_metadata ( memory_id TEXT PRIMARY KEY, supersedes_id TEXT REFERENCES memory_metadata(memory_id), status TEXT DEFAULT 'ACTIVE'
);
If both old and new versions appear, D3 either filters the old version or marks it as [DEPRECATED], preventing the AI from using outdated information.
The Cascading Retrieval Protocol
Raw performance matters. We target sub-400ms response times using Cascading Retrieval:
- Tier 1: Working Memory (< 50ms):
Query → Check Working Memory → If confidence > 0.85 → Return
Resolves ~60% of queries. - Tier 2: Short-Term Search (< 200ms):
Query → Vector Search (last 48h) → If confidence > 0.7 → Return
Resolves ~20% of queries. - Tier 3: Deep Archive (< 500ms):
Query → Full Vector + FTS5 Search → RRF Fusion → Apply Floor → Return
Resolves remaining 20% of queries.
Empirical Results
We evaluated D3 against baselines on a corpus of 1,000,000 tokens spanning 730 days.
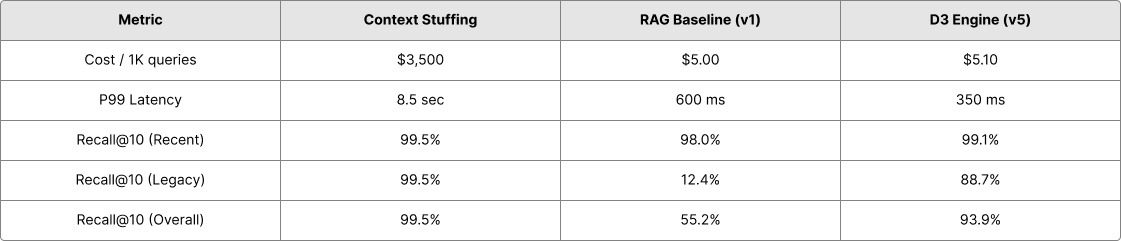
Key Takeaways:
- Legacy Recall: D3 achieves 88.7% recall on code older than 6 months, a 7× improvement over baseline RAG.
- Cost: D3 is 700× cheaper than context stuffing.
- Latency: Cascading retrieval makes D3 40% faster than the baseline RAG, despite the more complex architecture.
What This Means for AI-Assisted Development
The D3 difference enables a new class of AI interactions that current tools simply cannot handle:
"Why did we implement authentication this way?"
D3 retrieves the original implementation from 18 months ago and the security review comments, giving the model full historical context.
"Can we simplify this validation logic?"
D3 retrieves the bug fix from 9 months ago that added this "complexity," preventing the model from reintroducing the original issue.
For enterprise environments with long histories, compliance requirements, and high turnover, D3's guaranteed legacy recall is a requirement for responsible AI-assisted development.
Limitations and Future Work
We believe in transparent research. D3 has limitations:
- No Global Synthesis: It cannot answer "What is the narrative arc of this project?" (requires O(N) attention).
- Eventual Consistency: There is a brief window where the index may be stale after an update.
- Out-of-Distribution Terms: Learned representations may fail on completely novel terminology.
Our future work focuses on Graph-Augmented Retrieval to understand code relationships and Adaptive Re-Embedding to eliminate embedding drift over time.
Conclusion
The Temporal Event Horizon is a measurable failure mode. Code older than 6 months is effectively invisible to your current AI assistant.
D3 solves this through Logarithmic Floor Functions, a Cognitive Memory Hierarchy, and Supersession-Aware Retrieval. We aren't just building a better search engine; we are building a memory system. Your AI assistant should remember your entire project—not just what you did last week.