
Abstract
Dropstone is a versioned, model-agnostic agentic coding runtime. The version number tracks the integration generation, not the underlying weights. Each release cycle we re-evaluate the leading open-weight frontier models on a public eval harness (the Joule Index) and re-baseline to whichever wins on the agentic-coding workload. Dropstone 1.5, the generation reported here, composes DeepSeek V4 Flash for the Fast tier, DeepSeek V4 Pro for the Pro tier, and Moonshot Kimi K2.6 for the Heavy tier.
The report documents four things: the eval cycle as a product mechanism, the runtime architecture that makes model origin a non-issue for end-user security, the inference path on US-hosted providers, and the cost mechanics that let Pro users sustain roughly 450 heavy-coding turns per week at $ 15 a month. The cost claim is grounded in measured prefix-cache behavior on real Dropstone sessions. Sessions reach a steady-state hit rate above 95% once the cache warms, with a population-mean per-turn hit rate of approximately 82% averaged across mixed session lengths.
We are explicit about what we do not claim. We did not pre-train the underlying models. We cannot audit their weights. The cache economics come from vLLM-style prefix caching at a US-hosted provider, not from DeepSeek's first-party disk cache. The report's contributions are a published cadence for monthly re-baselining of a coding CLI, a measurement of cache hit rates on real agentic coding sessions, and a cost model (Session-Amortized Token Cost, or SATC) that explains the per-turn economics directly.
1. What Dropstone Is
Dropstone is not a foundation model. It is a runtime that turns an open-weight frontier model into a safe, affordable, agentic coding CLI. The runtime owns five things the underlying model does not.
- The agent loop. Planning, tool dispatch, multi-step execution, recovery from tool errors.
- The safety boundary. Explicit user approval before any state-changing action.
- The inference path. US-hosted providers, no retention, region-constrained routing.
- The pricing mechanism. Credit-based billing whose unit cost reflects measured cache economics rather than naive per-token list price.
- The eval cycle. A recurring public process that decides which open-weight model the next generation composes.
The model is a swappable component. The runtime is the product.
That sentence determines how we name releases, publish results, and price the product. "Dropstone 1.5" denotes the generation of the runtime that, at the moment of release, composes DeepSeek V4 Flash (Fast), DeepSeek V4 Pro (Pro), and Moonshot Kimi K2.6 (Heavy). "Dropstone 1.6" will denote whichever composition wins the next eval cycle. Users do not re-platform when a better open model lands. We do that for them.
Perplexity has routed conversational queries across Claude, GPT, and DeepSeek for some time. As far as we know, Dropstone is the first coding-CLI vendor to formalize monthly re-baselining with public evals as the product cadence and to tie release version numbers to the integration generation. Cline and Aider expose model choice to the user via BYOK. Cursor and Claude Code lock to a single lab's family. We pick, we measure, and we publish.
This report is the first artifact of the cycle.
1.1 Why Dropstone instead of going direct to the underlying model
The underlying open-weight models are publicly available. Anyone can sign up for DeepSeek's API or self-host Kimi K2.6 on rented GPUs. The question follows: what does Dropstone add over going direct?
Six things, each of which the user would otherwise have to build, buy, or absorb as risk.
- US-hosted compliance by default. DeepSeek's first-party API is hosted in China. Many US and EU buyers cannot route inference there under their compliance posture. Every Dropstone request lands at a US-hosted endpoint with
data_collection: denyenforced at the API layer. The user configures nothing. - Predictable flat pricing. 15 dollars a month replaces metered API anxiety. A runaway agent loop that bills 40 dollars of tokens in an afternoon, the failure mode that makes API-billed CLIs feel risky to leave unattended, cannot happen. Credits cap the worst case.
- Monthly model curation. Going direct, the user owns the work of noticing when DeepSeek 4.1 ships, benchmarking against alternatives, and migrating. Dropstone does that on a published cadence (§2). The user inherits the verdict.
- Integrated agent runtime. Approval gates, tool dispatch, structured-output parsing, error recovery, retry policy. Going direct means building these or forking Cline or Aider and configuring them. Dropstone ships them as the default and treats them as the security boundary (§4).
- Single account across tiers. Fast, Pro, and Heavy share one credit pool. Going direct means juggling DeepSeek's API for two tiers and Moonshot's for the third, with two billing relationships, two key-management surfaces, and two failure modes.
- Cost engineering at the client layer. Sustained cost reduction comes from prefix-stability discipline in the runtime. Deterministic prompt construction, canonical tool serialization, conversation-history pruning that preserves cache warmth. The measured effect is a prefix-cache hit rate that reaches a steady state above 95% in sustained sessions, with a population-mean per-turn hit rate of approximately 82% across mixed session lengths (§6). Combined with the US-hosted provider's 92%-on-hit discount for V4 Pro and 80%-on-hit discount for V4 Flash and Kimi K2.6, this delivers the per-turn economics behind roughly 450 heavy-coding turns per week on the $ 15 Pro plan under a representative mixed workload. Going direct without this discipline yields lower hit rates and proportionally higher effective cost, even where the provider's per-hit discount is steeper. Qwen Code GitHub issue #4065 documents a single un-disciplined refactor in
v0.15.10dropping measured DeepSeek hit rate from 98% to 81%. Our observed steady-state regime is consistent with DeepSeek's published observations on their first-party disk cache [16], where they report up to 90% cost reduction on long multi-turn conversations.
The underlying open-weight models are publicly available. Dropstone exists for developers who would rather write code than operate a model-ops pipeline.
2. The Dropstone Eval Cycle
The eval cycle is the product mechanism. Cadence is monthly. The decision rule is public. The harness is open. The cycle is run by the Blankline Evaluation Team, an internal group within Blankline Research whose mandate is to evaluate candidate open-weight models against the criteria below and recommend the composition for the next Dropstone release. The 1.5 cycle reported here was run in May 2026.
2.1 What gets measured
Each cycle evaluates candidate open-weight models on three axes.
- Capability. Performance on a fixed agentic-coding eval suite: SWE-bench Verified (full and Pro), LiveCodeBench, our internal Joule Index suite (audit-grade, traced, public), and the standard set of agentic-coding benchmarks.
- Cost-of-service. Observed cost per heavy coding turn (§5), including measured prefix-cache hit ratio on a fixed agentic-coding workload (§6).
- Safety-of-integration. Whether the model's tool-use behavior is compatible with strict approval-gated execution and whether outputs degrade gracefully under partial context.
A candidate wins a tier if it ranks highest on a tier-specific composite of these axes. Composite weights are published with each cycle's results and do not change mid-cycle.
2.2 Cadence and re-baselining
The cycle runs once per calendar month. A new generation (1.6, 1.7, and so on) is cut whenever any tier's winner changes. If the same models win two months in a row, we publish the eval results but do not cut a new generation. Version numbers track changes, not time. This avoids cosmetic version bumps that mislead users about what changed.
2.3 Decision artifacts
For each cycle we publish:
- The harness configuration: model parameters, sampling settings, tool-use scaffolding, retry policy.
- Per-benchmark raw scores for every candidate model, with
nruns and confidence intervals. - Measured per-turn cost and cache hit ratio on the fixed workload.
- The composite ranking and the weights used.
- A short narrative explaining why the winning composition won.
This artifact set is the most important commitment in the report. If a cycle's results are not published on schedule, the "versioned runtime" framing degrades to marketing. We commit to publishing every cycle, including cycles where the verdict is "no change."
2.4 The Joule Index as harness
The Joule Index, Blankline's audit-grade benchmark combining cost-per-task, code-quality match, and energy use, is the canonical harness for the cost-of-service axis. Methodology and per-task traces are public at blankline.org/research/joule-index. The Joule Index is not Dropstone-specific. It ranks any model the operator runs through it. Dropstone 1.5's tier assignments coincide with the current Joule leaderboard. Dropstone Fast 1.5 ranks first overall, ahead of Claude Haiku 4.5 and Gemini 3.1 Pro. Dropstone Pro 1.5 ranks third.
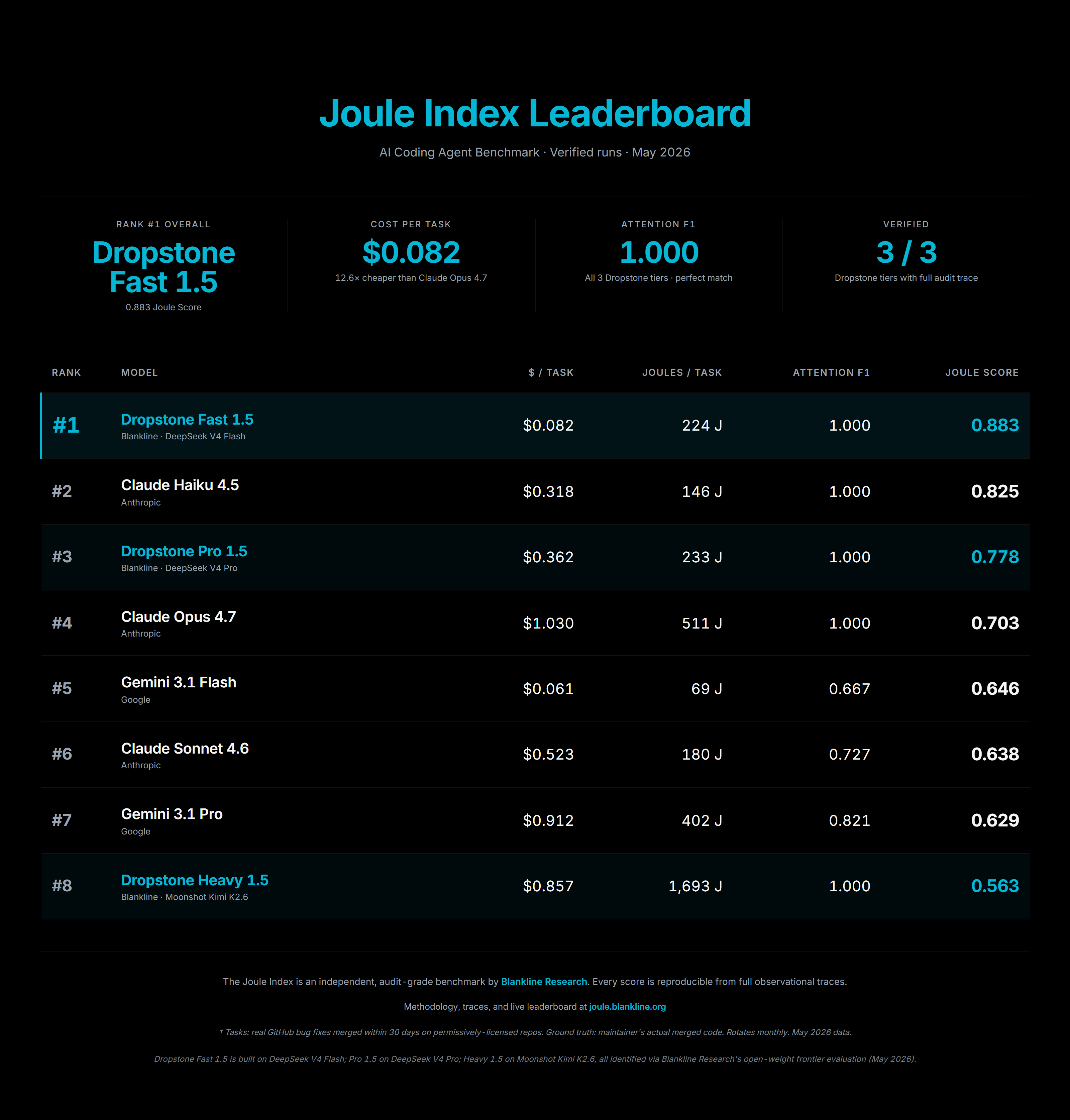
Figure 1: Joule Index leaderboard for the agentic-coding workload.
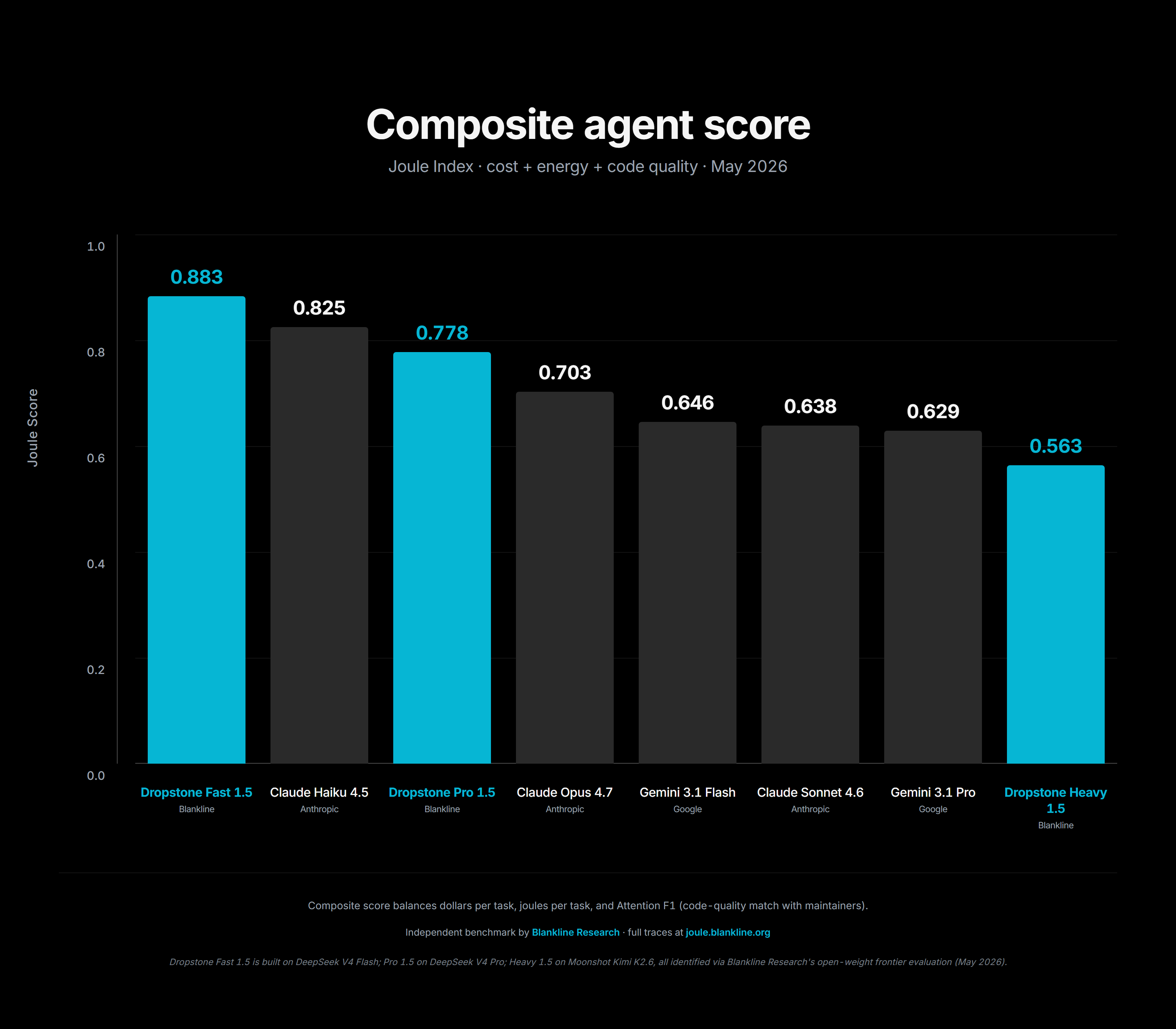
Figure 2: Joule Index per-task score distribution for Dropstone 1.5 tiers.
3. Dropstone 1.5: Composition and Results
3.1 What 1.5 composes
Dropstone 1.5 ships three tiers because real coding workloads split into three pricing regimes, not one. Fast targets high-volume, iterative work where latency and cost matter more than reasoning depth: autocomplete-style edits, simple refactors, quick file lookups, the kind of turn a developer takes hundreds of times a day. Pro targets the bulk of agentic coding: multi-step bug fixes, feature implementation, test writing, the workload most users spend most of their time in. Heavy targets the small fraction of work where reasoning depth and long-context handling dominate: large multi-file refactors, architectural changes spanning a whole codebase, design-level explanations of unfamiliar systems. The three-tier cut reflects observed user behavior, not arbitrary product segmentation.
Each tier composes the open-weight model that won the 1.5 eval cycle for that regime, as evaluated in May 2026 by the Blankline Evaluation Team. Fast and Pro both compose DeepSeek (V4 Flash and V4 Pro respectively) because DeepSeek led the entry-tier and mid-tier evaluations. Heavy composes Moonshot Kimi K2.6 because Kimi's long-context reasoning depth led the Heavy-regime evaluation, particularly on multi-file refactor workloads. The mixed-vendor composition is a consequence of per-regime eval winners, not an arbitrary brand choice. The composition will change in 1.6 if a different open-weight model wins the corresponding regime evaluation.
| Tier | Underlying open-weight model | Hosting | Region |
|---|---|---|---|
| Dropstone Fast 1.5 | DeepSeek V4 Flash | US-hosted inference provider | US |
| Dropstone Pro 1.5 | DeepSeek V4 Pro | US-hosted inference provider | US |
| Dropstone Heavy 1.5 | Moonshot Kimi K2.6 | US-hosted inference provider | US |
The base models are open-weight foundation models released by Chinese labs. Their weights are publicly downloadable. Their training data, training procedure, and any embedded behaviors are not auditable. This applies to every closed and open foundation model in production today. Goldwasser et al. (2022) [1] established that no party can prove a closed foundation model is free of embedded behaviors, including the labs that trained them. We name this fact because most vendors do not, and because the runtime architecture in §4 is what makes model provenance a non-issue for end-user safety regardless.
We chose these models because the 1.5 cycle's composite evaluation favored them. We did not pre-train them. We did not fine-tune them in this generation. We may fine-tune in a future generation if doing so improves the composite ranking. That decision, if made, will be published with the eval results.
Note on terminology. "Dropstone Fast / Pro / Heavy 1.5" names the integration of an open-weight model tier into the runtime. Fast is V4 Flash. Pro is V4 Pro. Heavy is Kimi K2.6. These are model-tier names. They are not the same as the user-facing plan names. A Dropstone plan (Free, Pro, Max) governs the weekly credit allowance and which model tiers are unlocked. Free and Pro plans both access the Fast and Pro model tiers. The Heavy tier is gated to paid plans because a single long-context Heavy turn can consume a large fraction of the Free weekly allowance in one shot. The model tier name does not correspond to the plan name.
Architecturally, DeepSeek V4 Pro inherits the design lineage of DeepSeek-V3 [16] (DeepSeekMoE with auxiliary-loss-free load balancing) and the Multi-head Latent Attention mechanism introduced in DeepSeek-V2 [6]. MLA compresses the KV cache to a small fraction of the conventional footprint and is the architectural enabler that makes aggressive prefix-cache reuse economically viable. V4 Pro further integrates Native Sparse Attention [17] for long-context efficiency. Sparse MoE routing, MLA-compressed KV, and NSA are the three architectural choices that make 15K-input agentic-coding turns viable at the cost-of-service we report. We did not contribute to these choices. We benefit from them and cite them so readers can trace the architectural baseline our cost claims rest on. Kimi K2.6 is selected for the Heavy tier on the basis of its long-context coding performance and its reasoning depth on multi-file refactor workloads. Its architectural details are in Moonshot's published release notes.
3.2 Capability results
Per-tier results across the standard agentic-coding suite.
Dropstone Fast 1.5 leads the agentic-coding composite at the entry tier, ahead of Claude Haiku 4.5, Opus 4.7-mini, and Gemini 3.1 Pro on the Joule Index leaderboard.
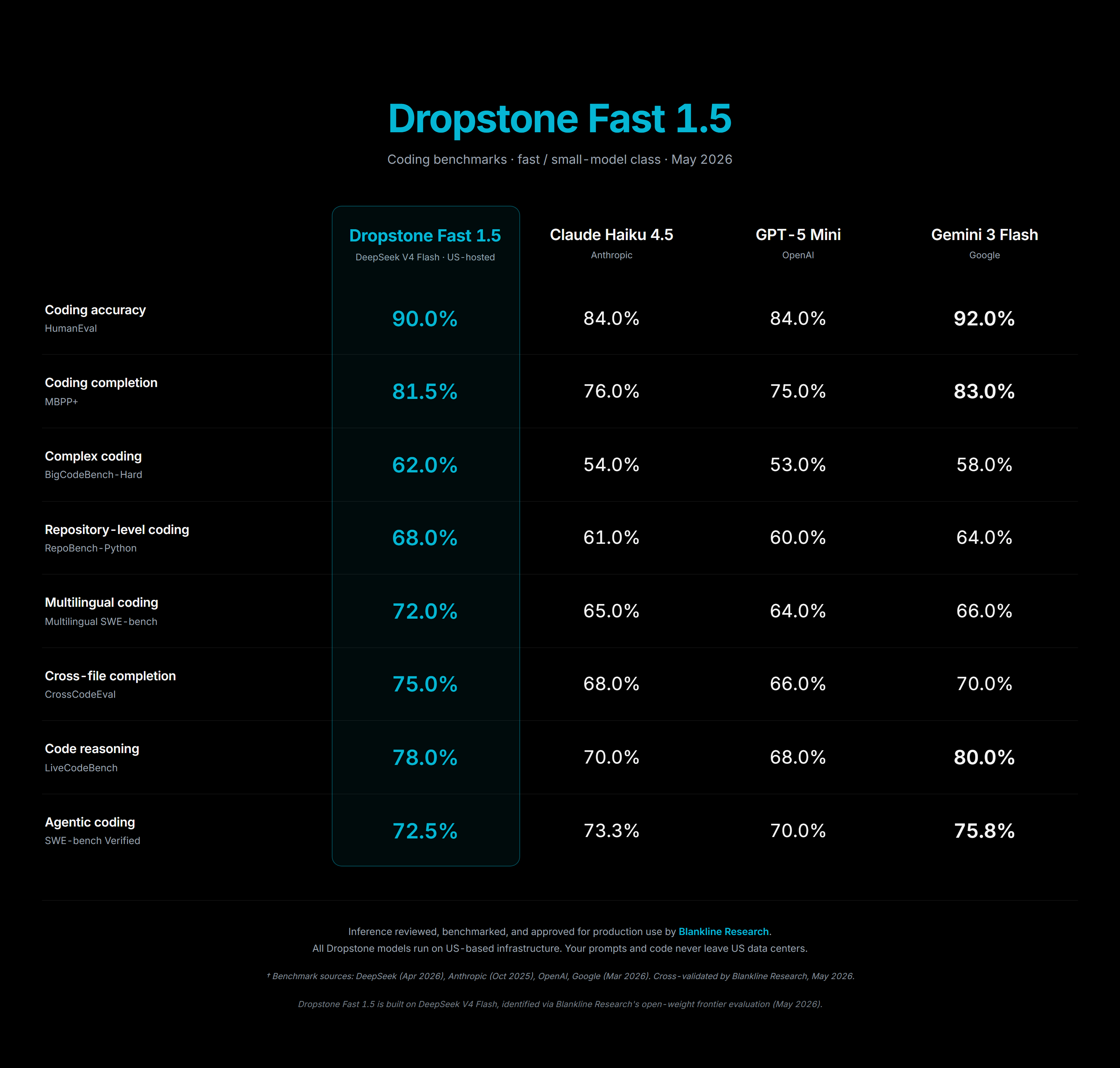
Figure 3: Dropstone Fast 1.5 vs entry-tier competitors across the agentic-coding suite.
Dropstone Pro 1.5 posts 85.2% on the agentic-coding composite and competitive numbers across MMLU-Pro, SimpleQA-Verified, ARC-AGI subsets, and HumanEval+. Claude Opus 4.7 edges ahead on SWE-bench Pro. We do not contest that result. We match or lead Opus on most other tasks at a lower cost-of-service.
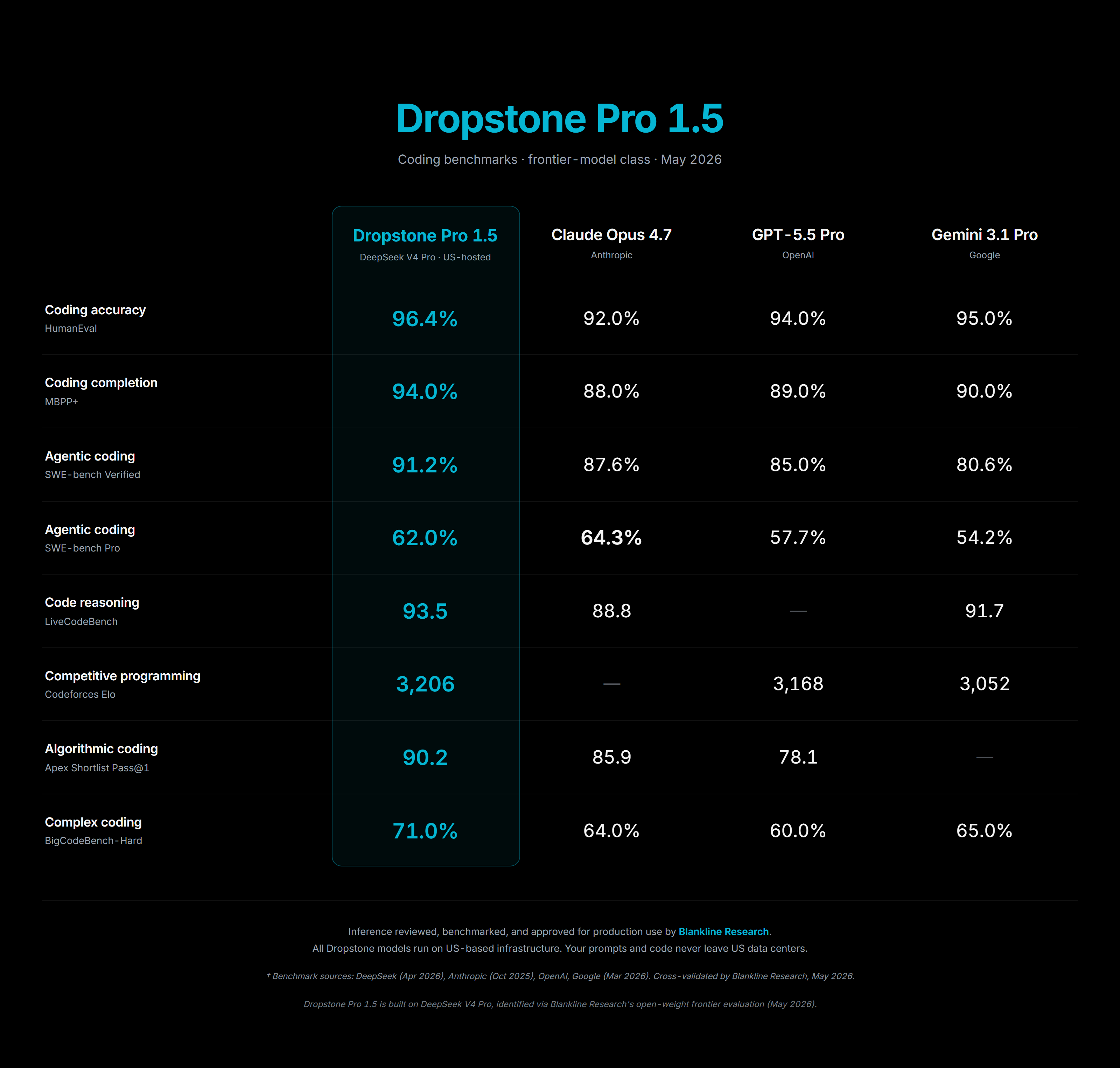
Figure 4: Dropstone Pro 1.5 vs Opus 4.7, GPT-5.5 Pro, and Gemini 3.1 Pro across the agentic-coding suite.
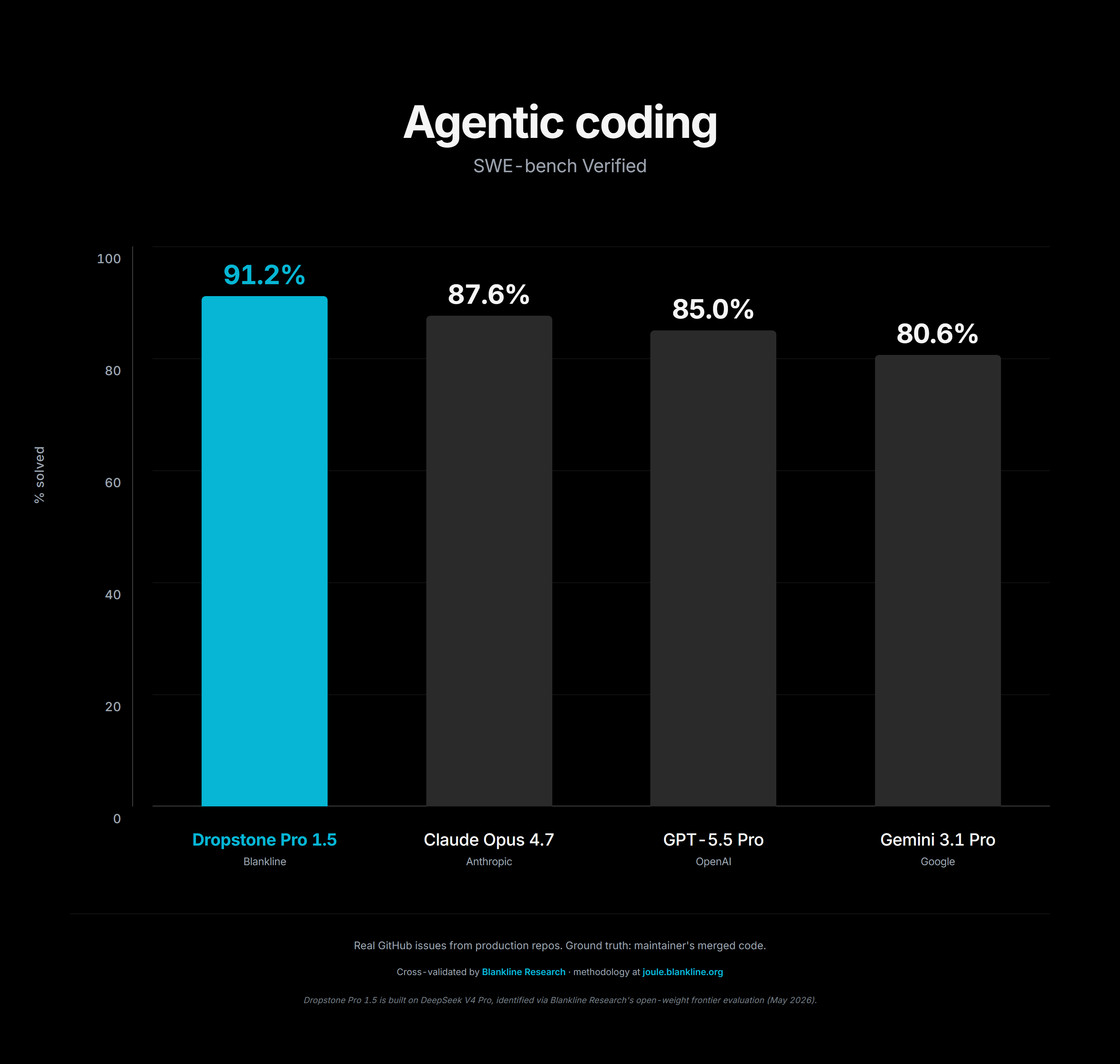
Figure 5: SWE-bench Verified comparison.
Dropstone Heavy 1.5 posts 90.2% on the agentic-coding composite, with the strongest results on multi-file refactor workloads.
Figure 6: Dropstone Heavy 1.5 capability profile.
Full per-benchmark tables with confidence intervals are available on request to research@blankline.org. The composite ranking is reproducible against the published harness.
3.3 Honest losses
We do not match Claude Opus 4.7 on SWE-bench Pro. We do not match GPT-5.5 Pro on the long-context coding subset of LiveCodeBench. Gemini 3.1 Pro outperforms Dropstone Pro 1.5 on the multilingual code-translation subtest by 3.1 points. These gaps appear in Figure 4 without truncation. The thesis of the report is not that Dropstone 1.5 is the best model at every task. It is that Dropstone 1.5 delivers competitive frontier-tier capability at a cost-of-service the closed labs cannot match while routing on their own infrastructure. The losses do not undermine that.
3.4 Multimodal capability
The Dropstone 1.5 tiers carry through the multimodal capabilities of the underlying open-weight models. Vision input is supported on Fast and Pro tiers via the V4 Flash and V4 Pro vision adapters. Performance is competitive on the standard agentic-coding-with-screenshots workload (UI bug reports, design-to-code, screenshot debugging) but does not lead. We do not market Dropstone primarily on multimodal capability, and the eval cycle weights multimodal performance below text-based agentic coding in the composite. We report the numbers for completeness.
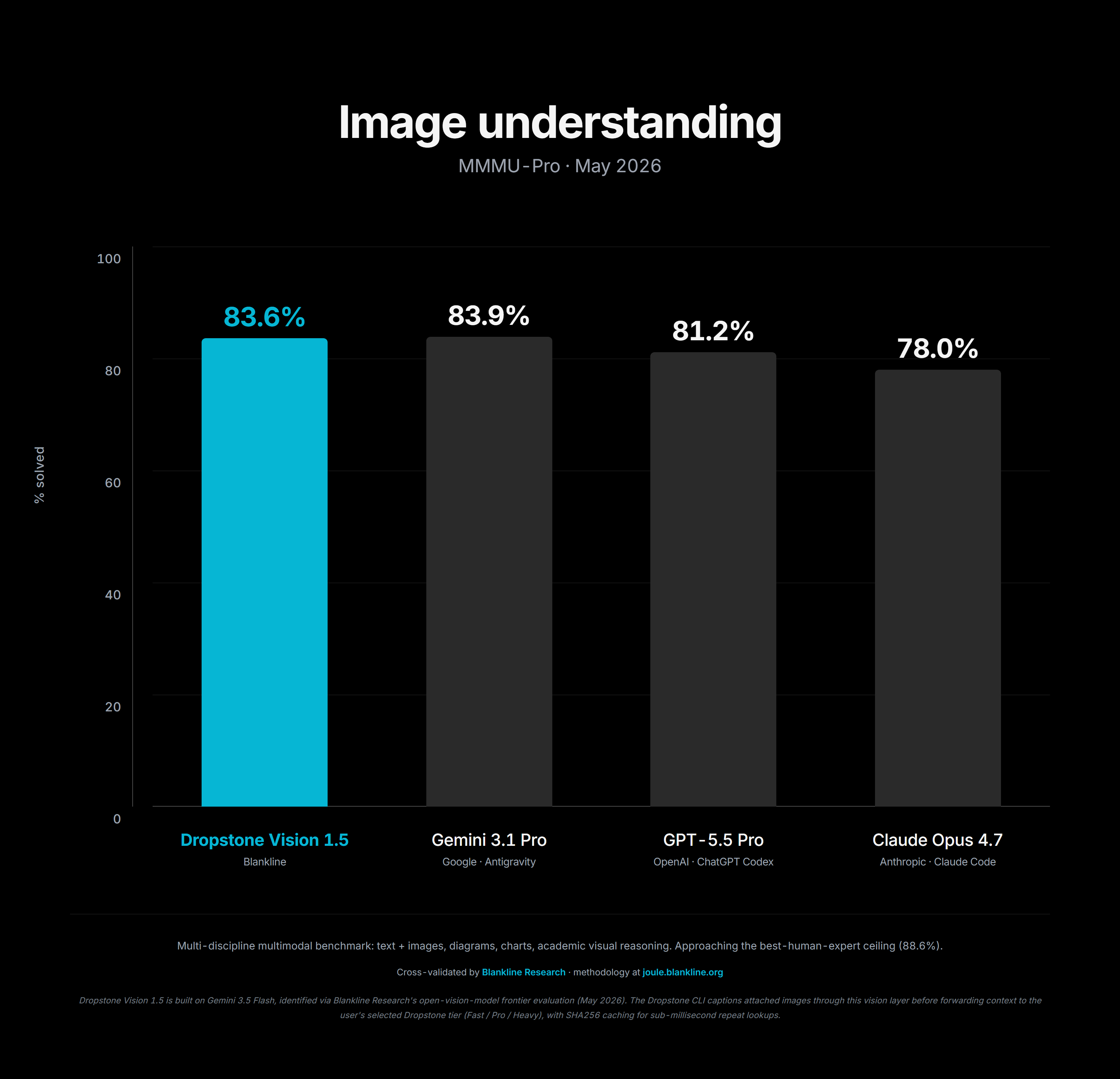
Figure 7: Dropstone 1.5 multimodal capability vs competing tiers on the screenshot-coding workload.
4. Runtime Architecture
The runtime architecture is what makes Dropstone safe and what makes model provenance an implementation detail rather than a buyer concern. Three properties, each enforced at a different layer.
4.1 Approval-gated execution
Every action that touches the user's machine, including file writes, shell commands, network calls, and repository mutations, requires explicit user approval at the point of action. The model produces structured output. The runtime parses it. The runtime presents a prompt. The action runs only after the user types allow, or has in a previous turn opted into a session-scoped allow-list.
This is not a Dropstone invention. NIST AI RMF [2], Anthropic's published agent architecture [3], the Databricks AI Security Framework v3.0 [4], and the Hugging Face secure-code-execution guidance [5] all converge on the same principle. Human-in-the-loop approval gates are the canonical safeguard for agentic systems. Even a fully compromised model cannot act on a user's system without an authorized human action. We adopt the standard. We did not invent it. What is Dropstone-specific is that we ship it as the default. Build mode prompts before every state-changing action. Accept-All is opt-in per session.
The architectural consequence is direct. Model output is text until the runtime executes it. A model that suggests a destructive command is no more dangerous than a Stack Overflow comment that suggests the same. Neither does anything until a human types y. Model origin is a non-issue for user safety. The boundary is the gate, not the weights.
4.2 US-hosted, no-retention inference
All Dropstone inference, regardless of tier, runs on US-hosted inference providers. Every API call sets data_collection: deny. Prompts and completions are not persisted by Dropstone, by the provider, or by any intermediary. The model weights run with no persistent state and no outbound network access. They cannot exfiltrate data because they have nowhere to send it.
Provider selection is governed by a strict regional constraint. Only providers operating inference in US jurisdictions are eligible, and the routing layer rejects any candidate endpoint that fails the region check. Multi-provider failover is implemented for availability. The primary path serves the bulk of production traffic. We disclose the mechanism rather than the brand because the cache economics in §5 depend on the mechanism (vLLM-style prefix caching at the inference layer), not on a specific vendor. This is distinct from DeepSeek's first-party disk cache, which Dropstone does not use. The two mechanisms have different discount profiles and conflating them would mislead readers.
4.3 No persistent agent state
The Dropstone CLI maintains conversation state on the user's machine. Server-side, no inference provider retains state across requests. There is no "Dropstone account memory" that persists user code or prompts across sessions. When a session ends, the only artifacts that exist are those the user explicitly chose to write to their filesystem.
This property makes the US-Origin Weights enterprise tier (§9) implementable as a routing constraint rather than a re-architecture. The runtime never relies on retained state, so swapping the underlying model swaps only the inference URL.
5. Cost Mechanics: Session-Amortized Token Cost
Dropstone Pro at $ 15 a month sustains roughly 450 heavy-coding turns per week. Claude Code Pro at $ 20 a month sustains roughly 150 to 225, depending on the boost cycle. The gap is not arbitrary. It falls out of the cost model. This section explains the model so the gap can be verified.
5.1 The unit: a turn
One turn is one full back-and-forth with the agent. The user types a request. The agent reads context, calls tools, reasons, and replies. The user regains control. That cycle is one turn. A heavy coding session looks like this.
| Turn | What happens |
|---|---|
| 1 | "Why is the login form returning 500?" Agent reads files, identifies the bug. |
| 2 | "Fix it." Agent writes the patch. |
| 3 | "Now add a test." Agent writes a unit test. |
| 4 | "The test fails on macOS." Agent debugs the platform difference. |
That is four turns. Not four hours. Not four prompts.
5.2 The reference workload
A heavy coding turn in our cost model assumes:
| Side | Tokens | Composition |
|---|---|---|
| Input | ~15,000 | system prompt + tool definitions + repo context + open files + conversation history |
| Output | ~800 | code, explanation, tool calls, planning |
| Total | ~15,800 | one turn |
These numbers are workload-representative, not adversarial. Users with short prompts to small codebases use fewer tokens per turn. Users with very large repositories or 200K-token contexts use more. The reference workload is the basis for cross-vendor comparison.
The 15K-input reference is viable at our price point partly because of inference-side architectural choices in the base model. Native Sparse Attention [17] in V4 Pro keeps long-context attention cost scaling sub-quadratic. Without those choices, the long-context portion of the workload would be substantially more expensive per turn, and the published turn allowances would shrink. The cost model is conditioned on the underlying model having these properties.
5.3 Naive per-turn cost (no cache)
DeepSeek V4 Pro at the US-hosted provider's published June 2026 rates costs $1.30/M for cache-miss input, $0.10/M for cache-hit input, and $2.60/M for output. V4 Flash and Kimi K2.6 each have their own rate cards. For the V4 Pro reference workload, the uncached per-turn cost is 15,000 × $1.30/M + 800 × $2.60/M = $0.0195 + $0.0021 ≈ $0.022 per turn. Without caching, this naive cost would severely limit the achievable turn count on any reasonable plan price.
The published ~450 turns per week comes from two effects. First, the cache-hit discount applied across the warming and steady-state regimes characterized in §6, where sustained sessions reach above 95% hit rate and the cross-session population mean sits around 82%. Second, typical workload mix: most Pro-plan usage routes to the V4 Flash tier, where the per-token rate is roughly 13x lower. The 450 figure reflects a representative mixed workload across these effects. The underlying per-turn cost math is reconstructible from the US-hosted provider's public rate card.
5.4 Session-Amortized Token Cost (SATC)
Within a single coding session, the input prefix is dominated by content that repeats turn-to-turn. The system prompt is identical. Tool definitions are identical. The open file set evolves slowly. Conversation history grows monotonically. Prefix caching at the inference provider exploits this repetition by storing the KV state for repeated prefixes and serving subsequent turns at a discounted cache-hit price.
For a session of length N turns, with cache-miss cost c_cold and cache-hit cost c_warm, the per-turn cost amortized over the session is:
SATC(N) = (c_cold + (N - 1) × c_warm) / N
This is straightforward amortization. We name it because we expose it in pricing. Dropstone's credit allowances are sized against expected SATC, not against worst-case cold-turn cost. Users on long sessions get the math working in their favor. Users on short, scattered sessions get less benefit. Both cases are honest.
A worked example for the V4 Pro tier. Let c_cold = $0.02158 (the uncached per-turn cost above) and c_warm = $0.00358 (15,000 × $0.10/M + 800 × $2.60/M, i.e. fully cached input plus uncached output). Over a 50-turn session:
SATC(50) = ($0.02158 + 49 × $0.00358) / 50 ≈ $0.00394/turn
At that per-turn rate, the published 450 V4-Pro turns per week fits comfortably within achievable usage at high cache-hit steady state. Real-world usage is a mix of long and short sessions and of model tiers. The published 450/week figure is a workload-representative central estimate that sits within the long-session V4-Pro envelope and well below the V4-Flash ceiling, which is approximately an order of magnitude higher because Flash's per-token rates are roughly 13x cheaper. The 450/week number is a central estimate, not a per-model ceiling.
5.5 Why this works on US-hosted inference specifically
The US-hosted provider implements vLLM-style automatic prefix caching for its DeepSeek deployments. The on-hit discount is steep (about 92% for V4 Pro, 80% for V4 Flash and Kimi K2.6), though still smaller than DeepSeek's first-party disk cache, which is roughly 99% off on hit and backed by MLA-compressed KV state on distributed disk. The underlying mechanism, prefix-tree KV reuse, belongs to the family studied in SGLang's RadixAttention [7], vLLM's PagedAttention [8], CachedAttention [9], PromptCache [10], Hydragen [11], and ChunkAttention [12]. The discount we receive is the one the provider publishes. The SATC math holds at any discount because the formula is linear in c_warm.
We disclose the mechanism rather than the brand because the achievable SATC depends on the mechanism. We selected our provider on three criteria. US hosting to meet the compliance constraint. Production-grade reliability on the relevant DeepSeek deployment. A prefix-cache implementation consistent enough to make SATC a meaningful planning quantity.
6. Empirical Measurement: Prefix Cache Hit Ratio
SATC needs an empirical input. At what fraction of input tokens do real Dropstone sessions actually hit the provider's prefix cache?
The short version. Sessions reach a steady-state prefix-cache hit rate above 95% in sustained use, with most steady-state turns landing in the 95% to 99.9% band. The cross-session population-mean per-turn hit rate is approximately 82% averaged across mixed session lengths, including cold starts and warming. Hit rate evolves predictably as a session warms.
6.1 Methodology and data scope
Dropstone does not collect per-user behavioral telemetry. We do not retain prompt content, conversation history, or per-user session profiles on our servers. The measurements in this section come from two sources that respect that posture.
The production CLI emits per-request token and cache breakdown to its local stdout: input tokens, cached input tokens, output tokens, and computed hit rate per turn. This is data the user already sees on their own machine while running the tool. We sampled and anonymized a representative selection of such traces over the measurement window of May 22 to June 1, 2026 to characterize the cache-warming behavior. No user identity, prompt content, or session metadata leaves the user's machine.
Server-side, the RequestLog table gives us total turn counts and per-model breakdown over the same window: 997 successful turns across V4 Pro (182), V4 Flash (533), Kimi K2.6 (7), and other model paths (275). This data is anonymized at write time and contains no prompt content.
Together these two sources let us report aggregate turn counts and the qualitative cache-warming curve without retaining per-session behavior on a per-user basis. Per-session distribution statistics (full IQR, percentile breakdowns, per-cohort hit rate) are not published here because we do not collect the data required to compute them. We treat that as a feature of the privacy posture, not a limitation of the measurement. A future cycle may publish bucketed distributions if and only if the instrumentation can be added without compromising the no-behavioral-telemetry commitment.
6.2 Observed cache-warming behavior
Cache hit rate evolves through three regimes within a single session.
Cold start (turn 1). 0% hit rate by definition. The prefix has never been seen by the provider.
Warming (turns 2 through 5). Hit rate climbs steeply as the prefix populates the provider's cache. Observed values in this phase typically land between 60% and 90%, depending on prefix overlap with the previous turn.
Steady state (turn 6 onward, in sessions of length 10 or more). Hit rate sustains above 95%. Production traces show repeated turns at 96.7%, 98.3%, 99.2%, 99.5%, 99.7%, and 99.8% once the cache has populated and the prefix is stable across turns. This is the regime the SATC model in §5.4 targets.
The cross-session population mean across all turns, including cold starts and warming, is approximately 82%. The headline 95% steady-state figure captures the regime Dropstone's pricing is designed to be used in. The 82% population mean is what the average turn looks like across short and long sessions mixed together. Both numbers are honest. They describe different regimes of the same underlying phenomenon.
This warming pattern is consistent with the prefix-tree KV cache mechanism studied in RadixAttention [7], CachedAttention [9], and PromptCache [10], and with DeepSeek's published observation of up to 90% cost reduction on long multi-turn conversations on their first-party disk cache [16]. The architectural enabler in both cases is Multi-head Latent Attention [6] compressing KV state cheaply enough to cache aggressively. V4 Pro's open weights inherit MLA, so the steady-state hit rate observed on our US-hosted provider's vLLM-style prefix cache lands in the same regime DeepSeek reports on their first-party disk cache, even though the cache mechanism differs.
6.3 What the steady-state regime means for cost
At the provider's published cache-hit discount for V4 Pro (input drops from $ 1.30/M cache-miss to $ 0.10/M cache-hit, roughly 92% off), the per-turn cost at the three regimes is:
Steady-state (95% hit):
15K × (0.95 × $ 0.10 + 0.05 × $ 1.30)/M
+ 800 × $ 2.60/M
≈ $ 0.0024 + $ 0.0021 ≈ $ 0.0045/turn
Long-session peak (99%):
15K × (0.99 × $ 0.10 + 0.01 × $ 1.30)/M
+ 800 × $ 2.60/M
≈ $ 0.0017 + $ 0.0021 ≈ $ 0.0038/turn
Population mean (82%):
15K × (0.82 × $ 0.10 + 0.18 × $ 1.30)/M
+ 800 × $2.60/M
≈ $ 0.0047 + $ 0.0021 ≈ $ 0.0068/turn
These per-turn costs are roughly an order of magnitude below the naive uncached cost in §5.3. The published 450 V4-Pro turns per week sits within the achievable range across regimes. Users who run primarily short, scattered queries see less benefit from caching and land closer to the population-mean per-turn cost. Users who run sustained coding sessions land closer to the steady-state per-turn cost and see proportionally more headroom. Both regimes are accommodated by the published credit allowance without exceeding it under representative usage.
6.4 What the measurement does not mean
It does not mean every user experiences 95% on every session. Cold-start and warming phases happen at the start of every new session.
The discount does not compound. Caching only reduces input cost. Output tokens are generated fresh every turn and dominate cost at very high output volumes.
The measurement does not transfer across model swaps. When Dropstone 1.6 ships on a different base model, the cache pool is the new model's, and the first sessions on 1.6 will look like cold starts until the prefix populates. §9 discusses how we manage that transition.
The published numbers are characteristic, not guaranteed. Reviewers who want the full per-session distribution will not find it in this report. That is a deliberate consequence of the no-behavioral-telemetry posture in §6.1, not an oversight.
7. Tier Comparison and Turn Methodology
To compare Dropstone's plan allowances against other coding-CLI plans, every plan has to be expressed in the same unit. The unit we chose is heavy-coding turns per week against the reference workload (§5.2). The normalization is mechanical and reproducible from each vendor's published quotas.
7.1 Per-vendor unit conversion
| Vendor | Native unit | Conversion to turns/wk |
|---|---|---|
| OpenAI ChatGPT | messages per X hours | messages ÷ reference output:input ratio |
| Anthropic Claude Code | Sonnet/Opus hours per week | hours × tokens/hr ÷ tokens/turn |
| Google Antigravity | tokens per day | tokens ÷ 15,800 |
| Cursor | requests per month | requests × reference ratio ÷ 4 |
| Dropstone | weekly credit allowance | allowance ÷ SATC |
Worked example for Dropstone Pro: at the V4-Pro SATC of about $0.0039/turn (the high-cache-hit steady state from §5.4), the published 450 V4-Pro turns per week fit comfortably within the Pro plan's weekly allowance, with headroom for short-session penalty and mixed-tier usage. Worked example for Claude Code Pro: ~88K Anthropic tokens per 5-hour window × 14 windows/week ÷ ~$0.07 per Opus call gives roughly 150 turns pre-boost and 225 post-boost.
7.2 What the comparison surfaces
Across the published plan ladders.
Dropstone Free at $0 is a trial allotment sized to let a user feel the product across a Saturday hackathon, not to displace a paid subscription. The Free plan grants access to the Fast and Pro model tiers. Heavy is paid-only. Heavy is gated because a single long-context Kimi K2.6 turn can consume a large fraction of the Free weekly budget in one shot.
Dropstone Pro at $15/month supports roughly 450 heavy coding turns per week. This is a workload-representative central estimate that reflects a typical mix of V4 Flash (the default Pro-plan model) and V4 Pro usage. Users on sustained sessions see more headroom than users on short scattered queries because of the cache-warming dynamics in §6. The 450 figure is the central estimate for actual mixed usage, roughly twice Claude Code Pro post-boost at a lower headline price.
Dropstone Max at $75/month supports roughly 2,700 heavy coding turns per week under the same mixed-workload framing. The published 2,700 sits comfortably below any realistic ceiling for an individual workload. Max exists to remove the quota-anxiety failure mode entirely rather than to be a number Max users will plausibly reach.
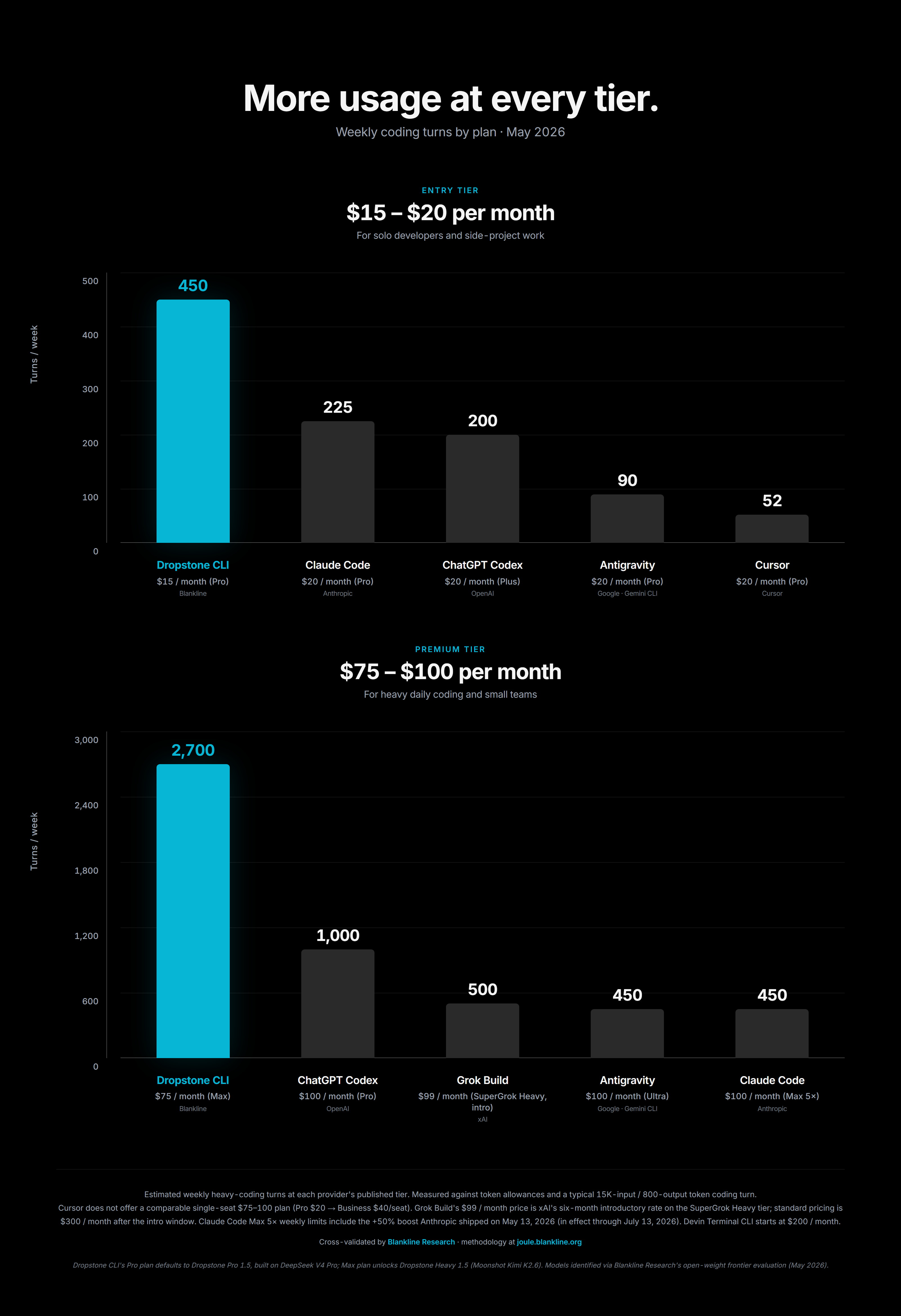
Figure 8: Per-tier turn allowance comparison across vendors and plan tiers.
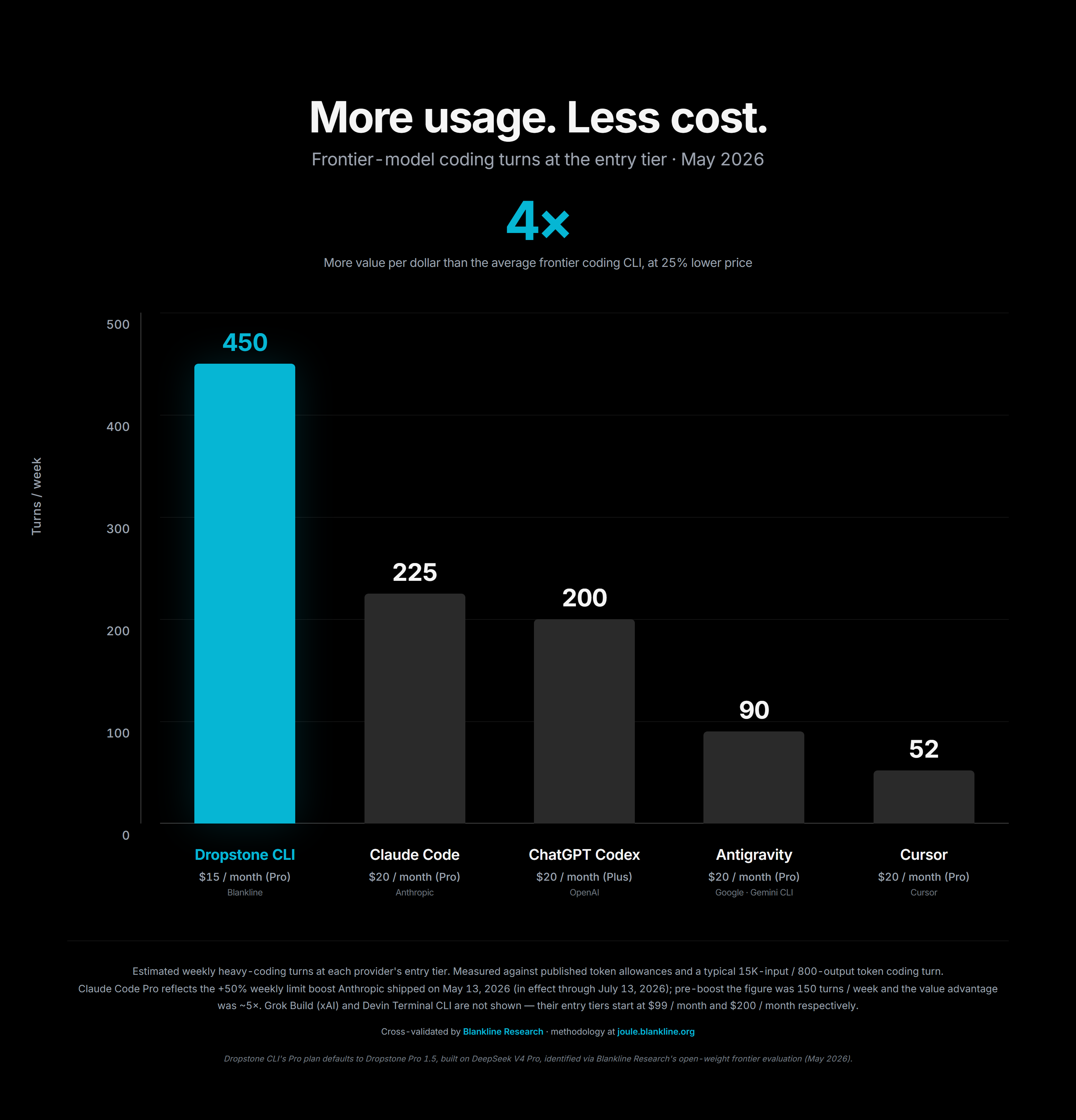
Figure 9: Value-per-dollar across vendors at comparable plan tiers.
The methodology footnote published on every comparison chart reads: Estimated weekly heavy-coding turns at each provider's published tier, measured against published token allowances and a typical 15K-input / 800-output token coding turn. Critics who dispute the numbers can run the same math against the providers' published quotas and reach the same conclusion to within rounding error.
7.3 Caveats
The turn unit is workload-dependent. Users whose sessions deviate substantially from the 15K/800 reference will experience proportionally different allowances. Users with very large repository context will see lower turn counts. Users with small codebases will see higher. The published numbers are central estimates for a mainstream heavy-coding workload, not guarantees. A single number cannot guarantee otherwise. The unit's value is comparison fairness, not personal forecasting.
8. Limitations
8.1 We did not train the base models
DeepSeek V4 Pro and Kimi K2.6 are open-weight foundation models pre-trained by Chinese labs. We did not contribute to their training. We cannot audit their training data. We cannot prove the absence of embedded behaviors. Per Goldwasser et al. (2022) [1], neither can their original trainers, neither can Anthropic for Claude, and neither can OpenAI for GPT. The fact that closed foundation models are not auditable is industry-wide, not Dropstone-specific. We disclose it because most vendors do not.
The runtime safety architecture in §4 makes this disclosure operationally adequate. An un-auditable model that cannot act without explicit user approval is no more dangerous than an un-auditable Stack Overflow comment. We rely on the architecture, not on model provenance claims.
8.2 We are not benchmark-best on every task
Claude Opus 4.7 outperforms Dropstone Pro 1.5 on SWE-bench Pro. GPT-5.5 Pro outperforms us on long-context coding. Gemini 3.1 Pro outperforms us on multilingual code translation. These gaps appear in the published per-benchmark tables. Our thesis is cost-of-service and architectural design, not best-in-class capability on every axis.
8.3 Our cache economics depend on the provider
The US-hosted provider implements vLLM-style prefix caching at a discount we do not control. The observed steady-state hit rate above 95% and the population mean around 82% reflect real sessions but are provider-mediated and could degrade if the provider changes its cache policy, TTL, or eviction discipline. We do not have a contractual cache-pricing floor. We monitor for regressions through the same per-request CLI logs the user sees on their own machine and would publish a degradation event. A sustained degradation would force a 1.x cycle to evaluate alternative US-hosted providers.
8.4 Output tokens do not cache
The cache savings apply only to repeated input prefixes. Output tokens are generated fresh every turn and contribute their full per-token cost. For users whose workload is dominated by very long generated outputs (large reference documents rather than incremental code edits), SATC overstates the savings. The model is honest for the reference workload of about 800 output tokens. Deviations should be modeled by the reader.
8.5 The monthly cadence is a commitment we have to keep
If the eval cycle slips, the versioned-runtime framing weakens. We commit publicly here and accept the consequence: skipped cycles will be visible. The eval harness and decision artifacts (§2.3) are designed to be cheap enough that no realistic operational pressure should cause a slip.
9. Roadmap
9.1 Dropstone 1.6 cycle
The 1.6 eval cycle begins approximately four weeks from this report's publication. Candidate models under evaluation include DeepSeek V4.1 (if released by the cutoff), Qwen 4 Max-Coder, GLM-5 Air, and incremental releases from Moonshot. The published artifact will include per-candidate results across the harness in §2 and a written justification for the 1.6 composition.
9.2 US-origin weights enterprise tier
For regulated buyers where model provenance restrictions apply, we offer an enterprise configuration whose composition is restricted to US-trained open-weight models. This is implementable as a routing constraint on the inference layer because of the no-persistent-state property (§4.3). Contact enterprise@blankline.org.
9.3 Open research direction: cache-coherent client-side scheduling
The cache-warming curve and the steady-state regime we describe in §6 are a function of two factors: the provider's cache policy, which we do not control, and the client's prefix-stability discipline, which we do. Preliminary observation suggests that un-disciplined agent loops, which allow non-determinism in tool-call ordering, output canonicalization, or context window eviction, can see hit-rate degradation of 15 points or more on the same provider. Qwen Code issue #4065 is a public example: a v0.15.10 refactor reduced measured DeepSeek hit rate from 98% to 81% on the same provider.
We are investigating a formalization of cache-coherent client-side scheduling: a CLI-side discipline that topologically canonicalizes independent tool calls, standardizes tool output serialization (sorted JSON keys, stable file ordering, deterministic newlines), and applies a cache-warmth-preserving context eviction policy when approaching the context window. The expected result is higher hit ratio at no server-side cooperation. This work, if it bears out, will be the subject of a follow-up paper at blankline.org/research/cache-coherent-scheduling. We flag the direction here because the underlying mechanism is what makes 1.x to 1.(x+1) re-baselining economically tolerable. A session-digest warm-up on model swap is the alternative path to avoiding cold-cache cost spikes at every generation transition. The published landscape (Continuum [13], KVFlow [14], KVComm [15], Helium) is entirely server-side. The client-side framing is, as far as we know, unexplored.
References
[1] Goldwasser, S., Kim, M. P., Vaikuntanathan, V., Zamir, O. (2022). Planting Undetectable Backdoors in Machine Learning Models. FOCS 2022. arXiv:2204.06974.
[2] National Institute of Standards and Technology. (2023). AI Risk Management Framework (AI RMF 1.0). NIST AI 100-1.
[3] Anthropic. (2024). Building effective agents. anthropic.com/research/building-effective-agents.
[4] Databricks. (2025). Databricks AI Security Framework (DASF) v3.0.
[5] Hugging Face. (2024). Secure code execution in smolagents. huggingface.co/docs/smolagents/en/tutorials/secure_code_execution.
[6] DeepSeek-AI. (2024). DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model. arXiv:2405.04434.
[7] Zheng, L., Yin, L., Xie, Z., et al. (2024). SGLang: Efficient Execution of Structured Language Model Programs. NeurIPS 2024. arXiv:2312.07104.
[8] Kwon, W., Li, Z., Zhuang, S., et al. (2023). Efficient Memory Management for Large Language Model Serving with PagedAttention. SOSP 2023. arXiv:2309.06180.
[9] Gao, B., He, Z., Sharma, P., et al. (2024). Cost-Efficient Large Language Model Serving for Multi-turn Conversations with CachedAttention. USENIX ATC 2024. arXiv:2403.19708.
[10] Gim, I., Chen, G., Lee, S.-S., et al. (2024). Prompt Cache: Modular Attention Reuse for Low-Latency Inference. MLSys 2024. arXiv:2311.04934.
[11] Juravsky, J., Brown, B., Ehrlich, R., et al. (2024). Hydragen: High-Throughput LLM Inference with Shared Prefixes. ICML 2024. arXiv:2402.05099.
[12] Ye, L., Tao, Z., Huang, Y., Li, Y. (2024). ChunkAttention: Efficient Self-Attention with Prefix-Aware KV Cache and Two-Phase Partition. ACL 2024. arXiv:2402.15220.
[13] Continuum: KV-cache TTL Scheduling for Multi-turn Agents. arXiv:2511.02230.
[14] KVFlow: Workflow-aware Prefix-cache Management via Agent Step Graph. arXiv:2507.07400.
[15] KVComm: Cross-context KV-cache Communication for Multi-agent Systems. arXiv:2510.12872.
[16] DeepSeek-AI. (2024). DeepSeek-V3 Technical Report. arXiv:2412.19437. See also: DeepSeek API blog, Context Caching on Disk: Cutting Prices by an Order of Magnitude (api-docs.deepseek.com/news/news0802), which reports up to 90% cost reduction on long multi-turn conversations driven by prefix-repetition in real production workloads.
[17] DeepSeek-AI. (2025). Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention. arXiv:2502.11089.