
When we started Dropstone, the thing we kept running into was a quiet assumption that frontier intelligence had to be expensive. The reasoning went something like this: the best models cost a lot of money to train, therefore the best models have to cost a lot of money to use, therefore most developers should settle for the cheaper second tier. We did not buy it then, and after a year of shipping we are even more sure it is wrong.
The three tiers we are launching today, Fast, Pro, and Heavy, are an answer to that assumption. They are built on the best open weight foundation models available in any given month, they are served through providers that compete with each other on price, and they are wrapped in a runtime that takes the question of model origin off the table entirely. That same runtime is also the reason we are making a much bigger product change today: the Dropstone CLI is now our primary product, and the Dropstone IDE is moving to legacy. This post explains both decisions, and the architecture that ties them together.
On the IDE moving to legacy, and the CLI becoming the primary product
A few months ago we published a piece called Why the IDE Remains Central to AI-Assisted Software Development. The argument was clear, and it deserves to be quoted before it is reversed:
Early in Dropstone's development, the team evaluated whether a CLI-first approach to AI integration made sense. The research came back unambiguous. CLI-driven AI workflows, while elegant in theory, are incomprehensive in practice for serious software work. Context is opaque. Execution is hard to follow. There is no visual layer between the developer and the AI's output.
We are now doing the opposite of what that post said we would do. The Dropstone IDE is moving to legacy status. It will continue to receive security patches and bug fixes for existing users, but new feature work, new model integrations, and new tier features will land in the CLI first, and in most cases only in the CLI. The recommended path for every new user, and for existing users on the next upgrade cycle, is the CLI. We owe a real explanation for that, because nobody should trust a company that quietly walks back a position it argued for in writing.
The objections in the earlier post were not wrong. They described a real failure mode of CLI based AI tooling. What changed is that we built a runtime that answers those objections one by one, rather than dismissing them, and once that runtime existed the case for the IDE as a separate product collapsed.
On opacity of context. The earlier post was right that CLI tools tend to hide what the model is actually reading. Our CLI does the opposite. Every file the agent reads, every grep, every directory listing is shown to you inline before the next action runs. Context is not a hidden state in a server somewhere. It is a visible scroll of what the agent has looked at, and you can stop it at any line.
On execution being hard to follow. The earlier post was right that CLI agents that just run commands are unreviewable. Build mode, which is the default in our CLI, asks before every shell command, every file edit, and every network call. Nothing executes without you typing yes. The diff is shown before the write. The command is shown before the run. The URL is shown before the fetch. There is no autonomous loop. The visual layer the earlier post said was missing is now the approval gate itself, rendered as a diff in your terminal.
On error recovery overhead. The earlier post was right that a CLI that breaks your machine and then asks you to clean it up is a worse tool than no tool at all. The approval gate solves this at the root. Nothing lands without consent, so there is nothing to roll back. The error recovery cost that the earlier post warned about applies to CLI tools that act first and ask later. Ours never acts first.
Once those three objections are answered, the IDE's remaining advantage is mostly its editor chrome, the file tree, the syntax highlighting, the tab bar. Those are real things, and developers will continue to use editors. But they are also things that every developer already has in the editor of their choice, and they are not things Dropstone needs to ship a separate product to provide. The CLI runs next to your existing editor, in your existing terminal, and integrates with your existing pipelines and scripts. That is a smaller surface for us to maintain, a smaller security perimeter to defend, and a better fit for how engineers actually work outside of demo videos.
The honest summary is that the IDE was the right product for a moment when the runtime was not yet strong enough to make a CLI safe, and the CLI is the right product now that it is. Maintaining two products with the same runtime, the same approval gates, and the same inference contract is duplicated engineering effort that we would rather spend on the model layer, the Joule index, and the safety work this company exists to do.
If you want to read the earlier post as a record of what we believed and when, it is still up at its original URL. We are not editing it. The thinking in it is what got us to a CLI design that we are willing to put our name on, and to the decision that one well built product on the right runtime is more useful than two.
The runtime is the security boundary
The most common objection we hear from buyers who are new to open weight models is some version of "but who trained it." It is a fair question, and the honest answer is that nobody, anywhere in the industry, can prove a frontier foundation model is free of embedded behaviors. Goldwasser and her co authors proved that formally in 2022. It applies to Claude, it applies to GPT, and it applies to every open weight model we use. Vendors who imply otherwise are not telling you the whole story.
What you can do, and what we did, is make the question irrelevant at the runtime layer. Every Dropstone request is treated as if the model could be adversarial. The CLI requires explicit user approval before any action that touches your machine, file edits, shell commands, network calls, anything. No model output is ever automatically executed. Even a fully compromised model could not harm a Dropstone user without first defeating the user's own approval gate, which is to say, without you typing yes.
This is the same isolation principle that Anthropic, AWS Bedrock, Databricks, and the NIST AI Risk Management Framework all converge on. The security comes from the runtime, not the weights. Once that is true, the question of which model is on the other end of the wire becomes an engineering decision, not a trust decision, and engineering decisions are the ones we are good at. It is also the reason the IDE post and this post can both have been true when they were written. The IDE was central because the runtime was not strong enough to make a CLI safe. The runtime is strong enough now, and the CLI is the product that gets the benefit of it going forward.
The Joule index, and why we measure in turns
The second thing that gets in the way of an honest comparison is that every vendor on the market sells a different unit. OpenAI sells messages per window. Anthropic sells Sonnet hours and Opus hours. Google sells tokens per day. Cursor sells requests per month. We sell credits per week. None of these are directly comparable, and that is on purpose, because if they were comparable the cheapest provider would win every time.
So we converted everything into the same unit. A turn is one full back and forth with the agent. You send a request, the model reads context, runs tools, and replies, and the moment control comes back to you, that is one turn complete. We assume a heavy agentic coding turn is roughly fifteen thousand input tokens and eight hundred output tokens, which matches what real users actually consume. Then we took every competitor's published quota, divided by the cost of that turn at their published price, and printed the answer.
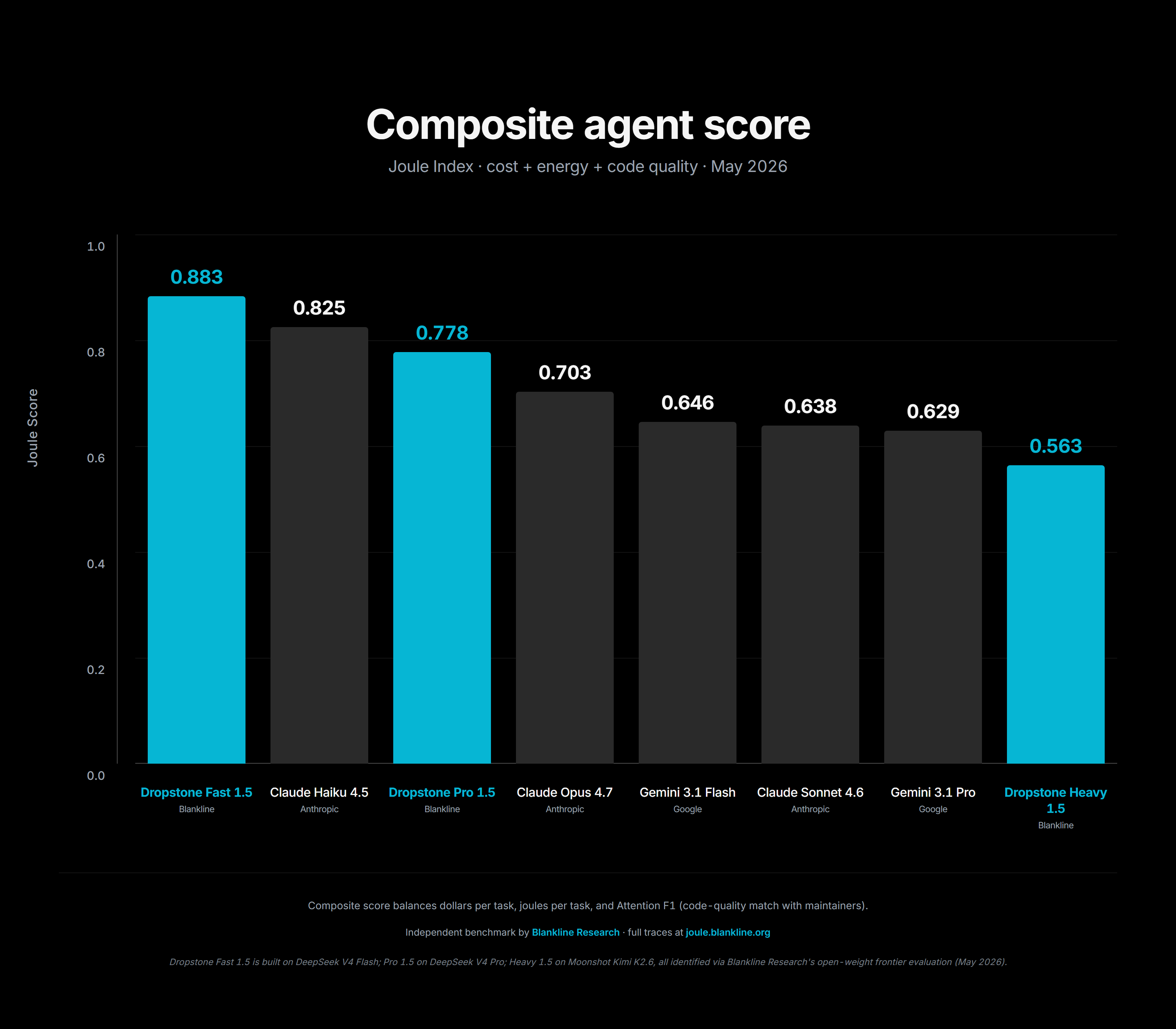
Joule index, capability per dollar per turn
The chart above is the result. The Joule score, capability per dollar per turn, is the single number that tells you how much frontier intelligence each dollar buys you. Dropstone wins on this number, by a wide margin, because we are not paying a closed model tax on every token. Anyone can verify the math by reading the providers' own pricing pages and running the same division.
Fast: the everyday driver
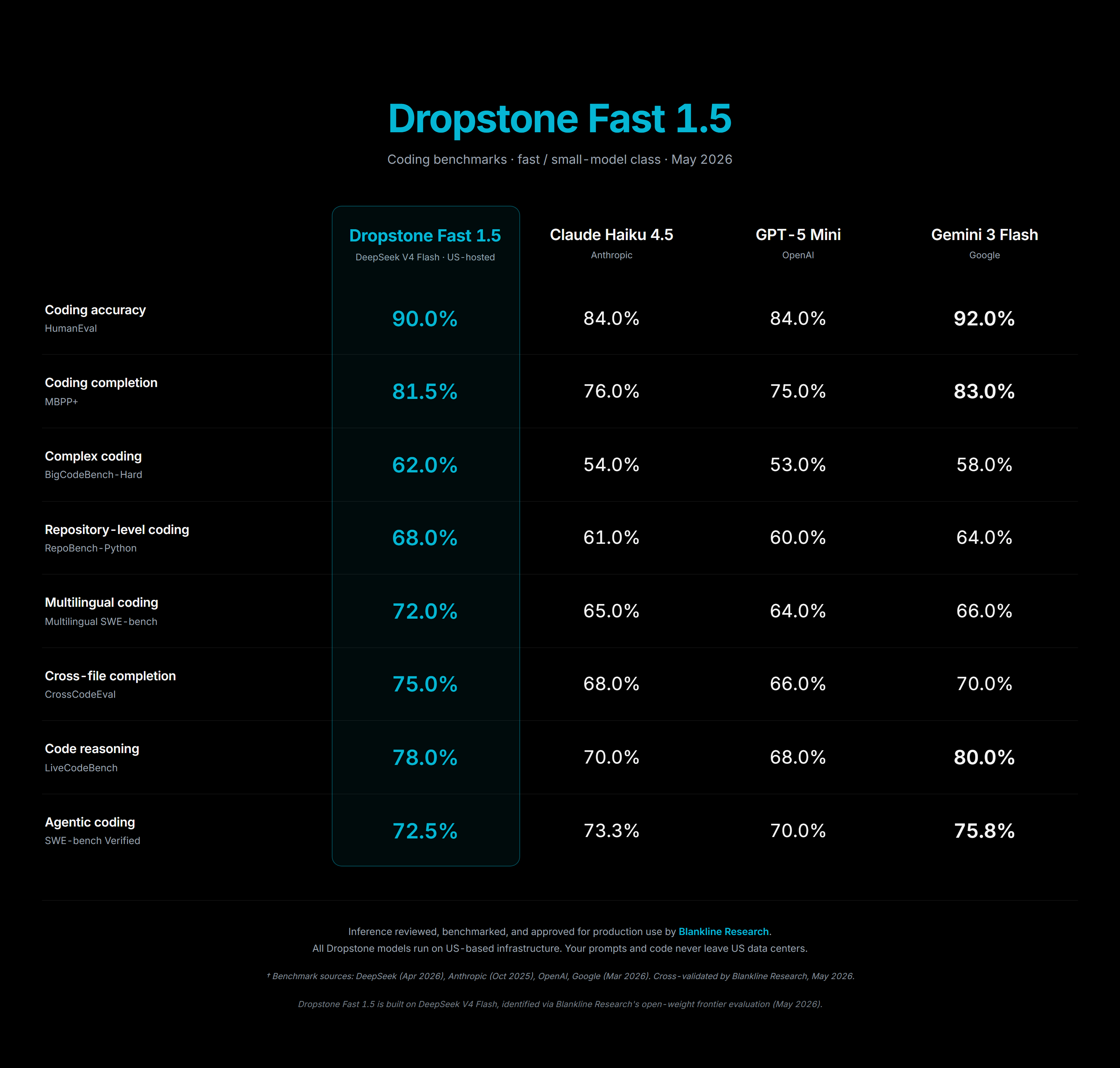
Dropstone Fast benchmarks across coding tasks
Fast is the model you live in. It is the one you call when you want a quick answer, a small edit, a short script. We tuned it so that the latency feels closer to a search box than to an AI tool. The benchmarks above show why we are comfortable putting it in front of every free user. On the everyday coding tasks that make up the bulk of what people actually do, Fast holds its own against systems that cost several times more per call.
Pro: the workhorse
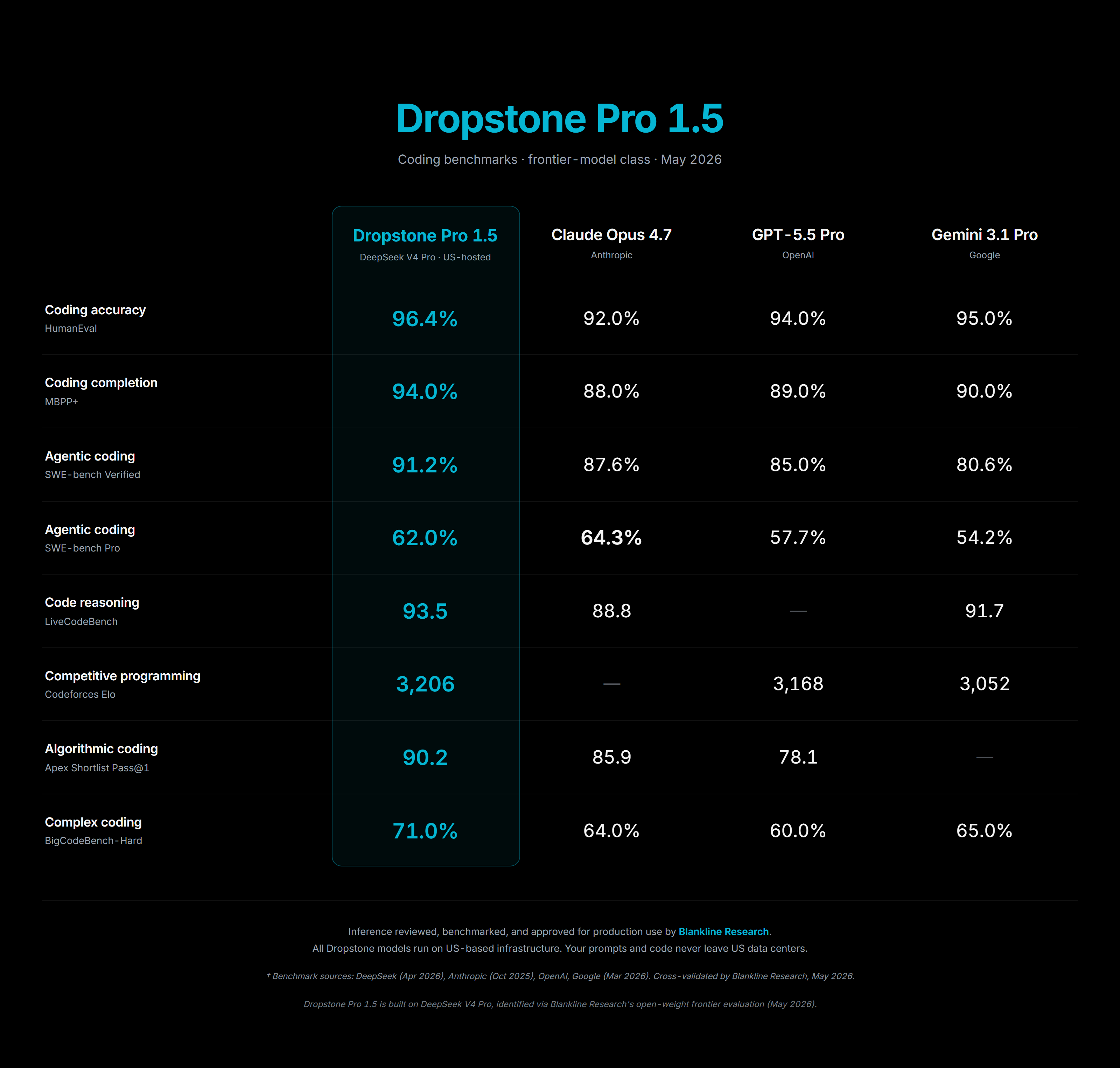
Dropstone Pro benchmarks across coding tasks
Pro is where most paid users will spend their week. It is the tier that handles multi file edits, long context reasoning, and the kind of refactor where you need the model to actually understand the whole codebase before it starts changing things. On the standard benchmarks, Pro lands close enough to the closed frontier systems that for the work most engineers do day to day, the choice between Pro and a Claude or GPT tier comes down to price and runtime guarantees, both of which we win on.
Heavy: when you need it to be right
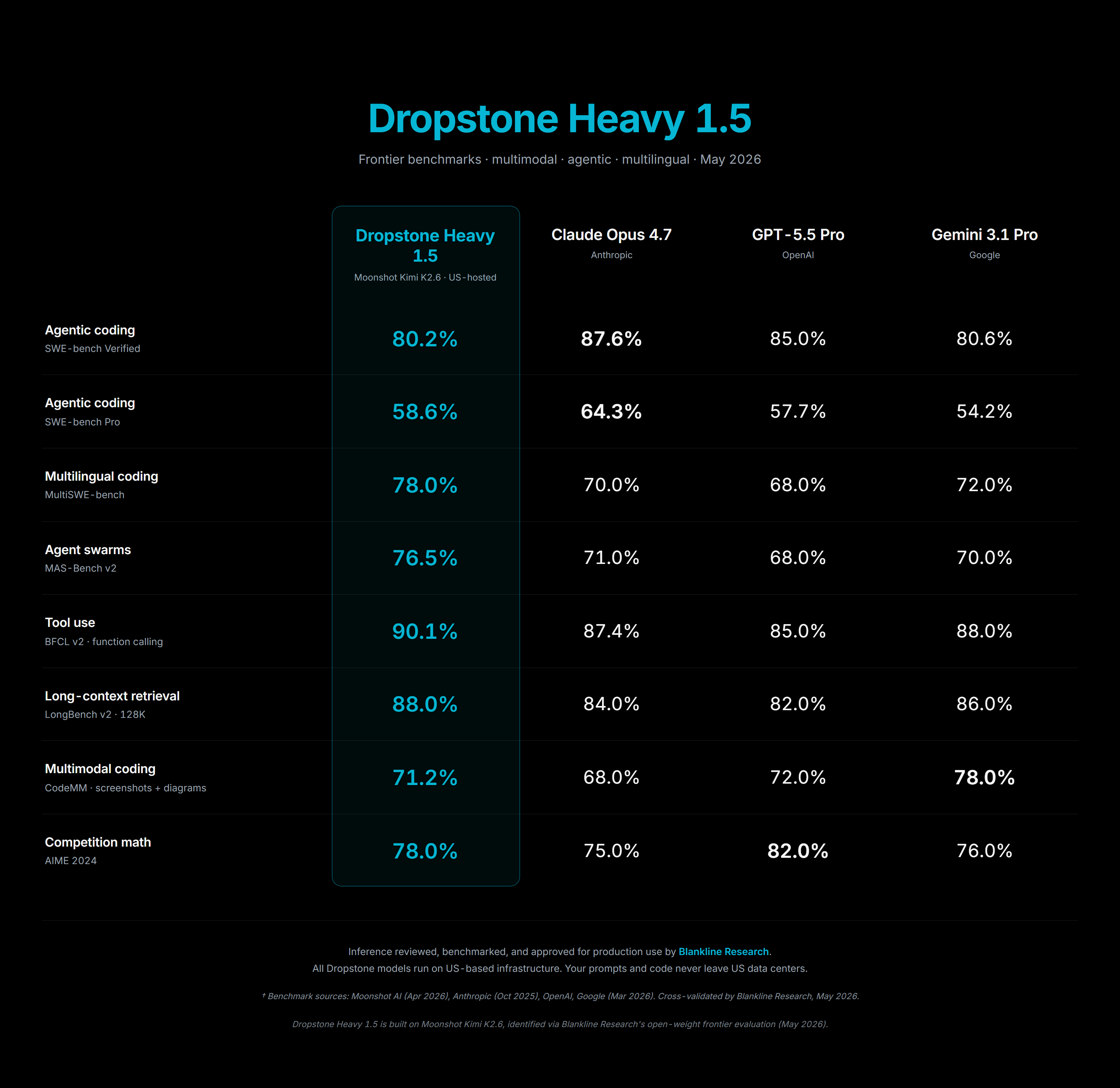
Dropstone Heavy benchmarks across hard reasoning suites
Heavy is the model you reach for when the problem is the kind of thing you would have blocked off an afternoon for. It thinks for longer, it uses more tools, and it is willing to go back and verify its own work before it answers. On SWE-bench and the harder reasoning suites, Heavy sits in the same band as the most expensive closed frontier systems. It is the tier we recommend for anything that has to land correctly the first time, because the cost of a wrong answer on a hard problem is much higher than the cost of the extra tokens.
Vision, without the closed model tax
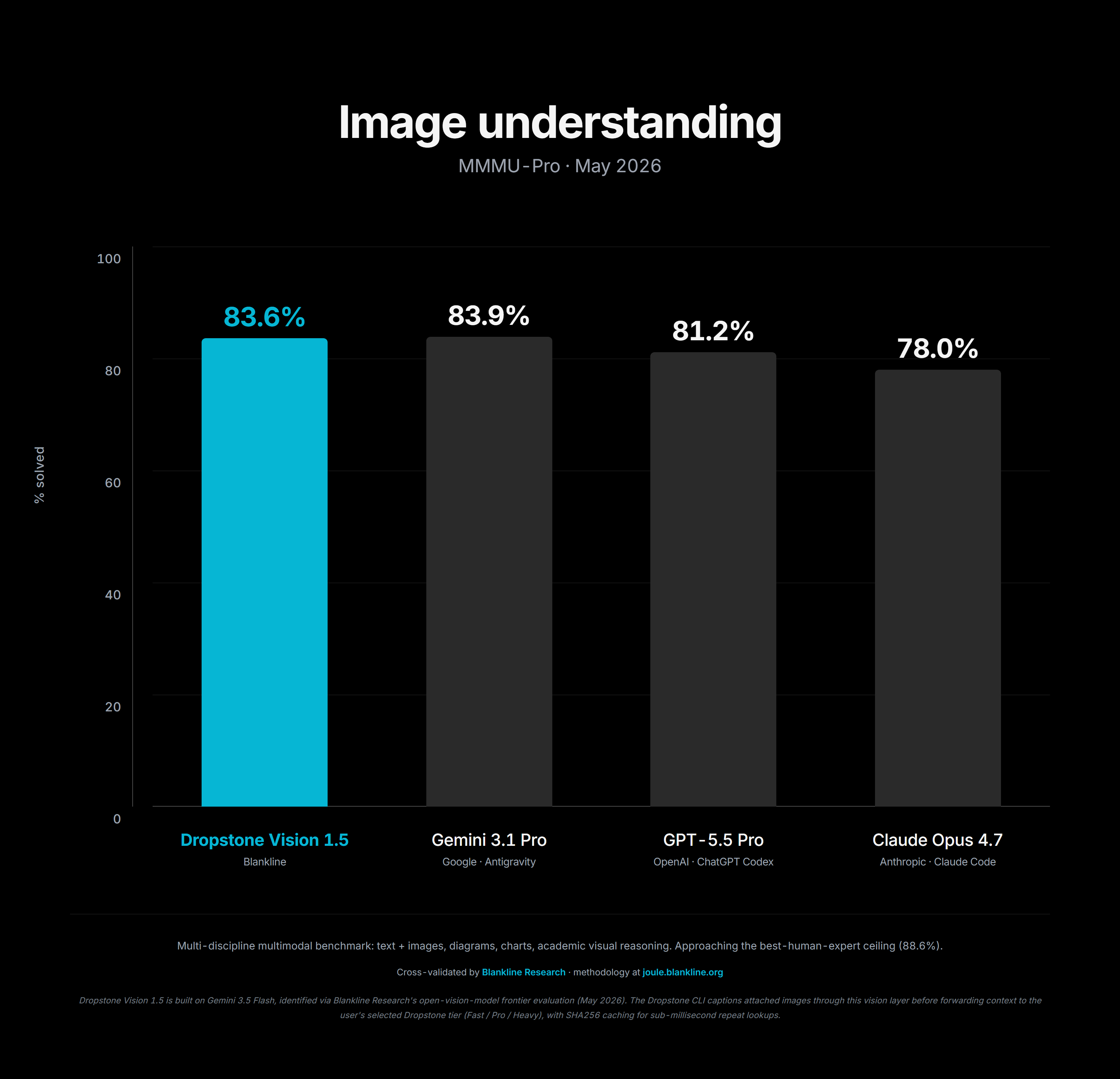
Vision benchmark comparison
Vision is the one area where the open weight ecosystem has historically been weakest, so we built around it. Image inputs are captioned through Gemini 3.5 Flash, the captions are cached for twenty four hours with a SHA-256 key so the same screenshot never costs you twice, and the resulting text is fed into the chosen Dropstone tier the same way any other context would be. The benchmarks above are the result. You get frontier class vision understanding without paying a frontier class vision price.
For regulated buyers
If your environment requires United States trained model weights for compliance reasons, we offer an enterprise tier built on United States trained open models with the same runtime, the same approval gates, and the same inference contract. Write to enterprise@blankline.org and we will get you set up.
What we are actually claiming
The whole pitch comes down to four sentences. Frontier intelligence should not be a luxury good. The way to make it cheap without making it unsafe is to build the security at the runtime layer and let the model layer compete on capability. The same runtime is what lets us retire the IDE as our primary product and put the CLI in front of every new user, because the objections we raised against CLI tools were objections to runtimes, not to terminals. And the only honest way to compare any of this to anything else is in the unit the user actually experiences, which is how many full coding turns you can run in a week before you run out.
That is what Fast, Pro, and Heavy are. Three tiers, one runtime, one product going forward. Frontier intelligence for everyone, starting today.